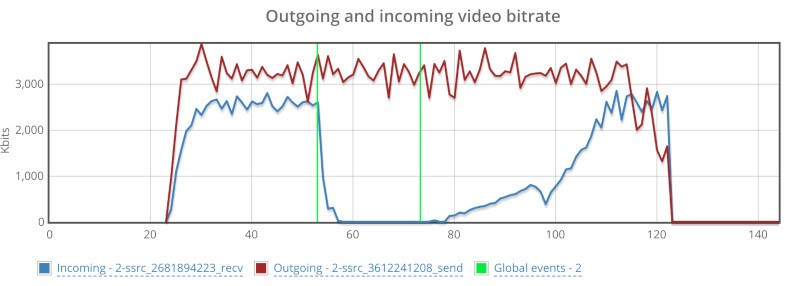
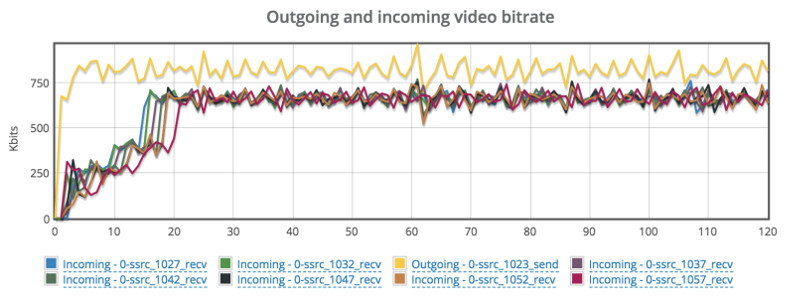
Understanding a call center agent’s network in a WFH world
As we settle into 2022, it seems like call center agents may continue in their WFH (work from home) mode even beyond the pandemic. This will be done either part time or full time, for some agents or for all of them.
The reasons for that are wide and varied, but that’s probably a topic for another time. This time, I’d like to discuss what we are going to do moving forward, to ensure that those reaching out to your call center get the best call quality possible, even when your agents are working from home.
The shift of the call center agent to WFH
Since the pandemic started, those who are able to work remotely have been directed to do so. That includes call center agents – the people who answer the phone when we want to complain, book, order, cancel or do a myriad of other activities in front of businesses.
The whole environment and architecture of the call center has changed due to the new world we live in today.
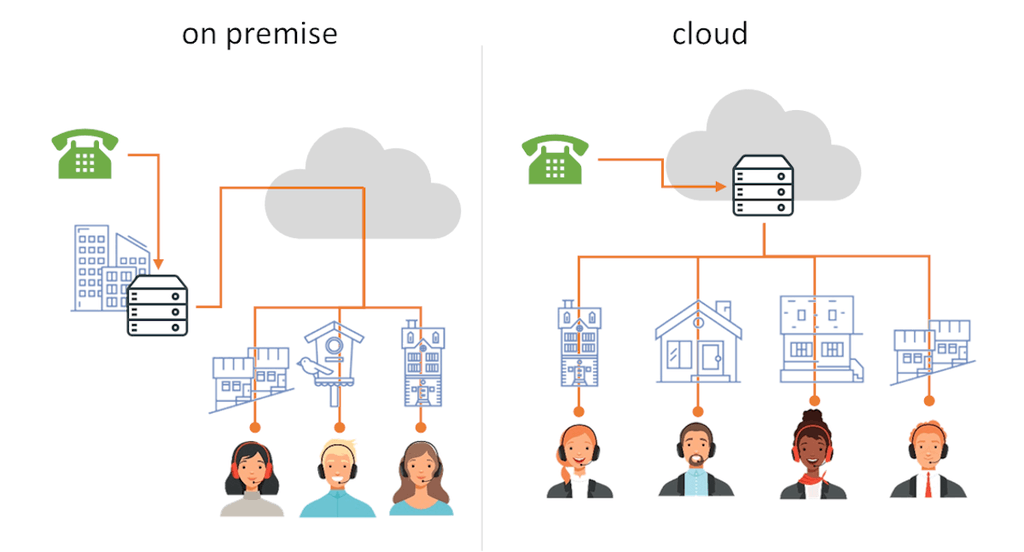
In the past, this used to be the call center:
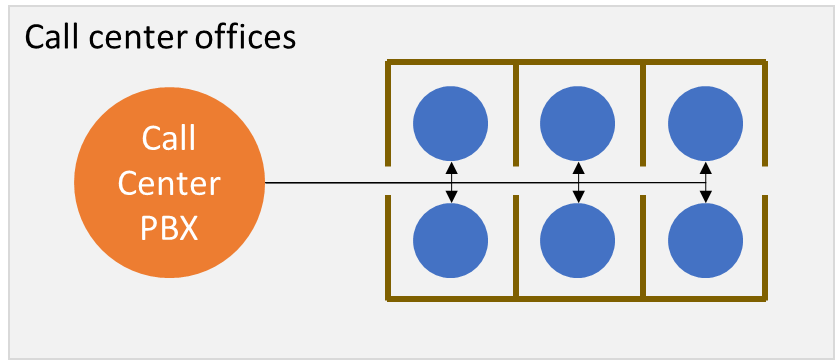
The call center PBX, the network connections to the agents, the agent’s environment (room), computer and phone have all been in our control and in our office facilities.
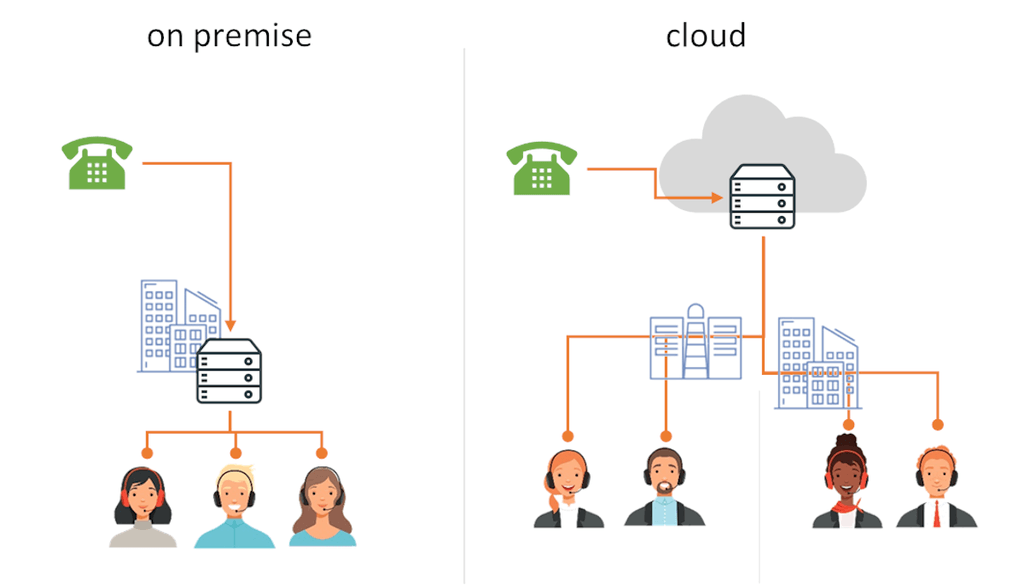
Now? It looks more like this for an on premise call center:
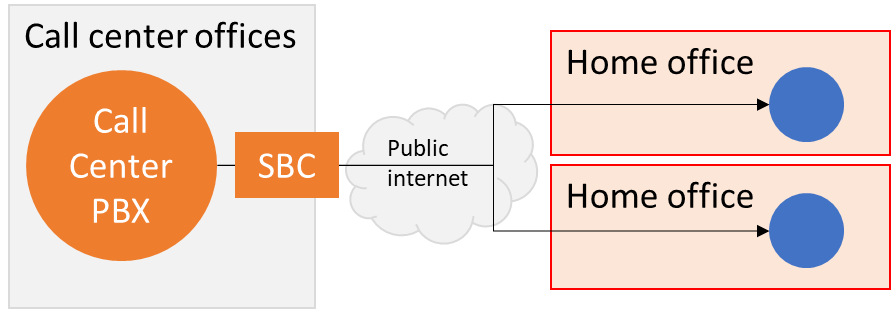
With an on premise call center and work from home agents, we’re likely to deploy an SBC (Session Border Controller) and/or a VPN to connect the agents back to the office. It adds more moving parts, and burdens the internet connection of the office, but it is the fastest patch that can be employed and it might be the only available solution if you can’t or don’t want to run your call center in the cloud.
Or this for a cloud call center:
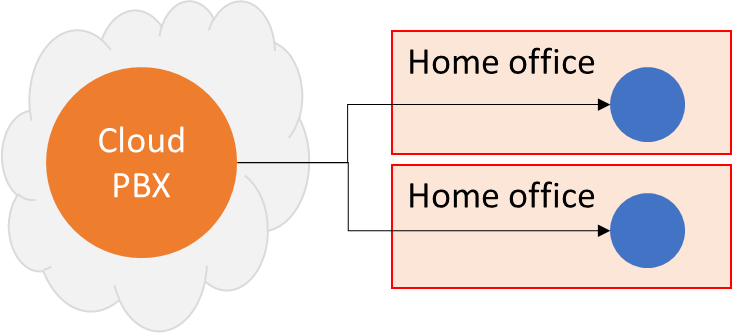
In a cloud call center, the agents connect directly to the cloud from their home office.
Just like the on premise call center, the cloud solution ends up with some new challenges. Mainly – the loss of control:
- We don’t control the network quality of the agent
- The environment of the agent is out of our control
- It is likely that the device and peripherals of the agent are still in our control. But that’s not always the case either
And, even with our best intentions in asking the agents to be on ethernet, on a good network and in a quiet environment, they can struggle with doing it well enough.
Can you hear me now?
With work from home call center agents our main challenge becomes controlling their home environment and network.

At home, agents will have noise around them. Kids playing, family members watching television, the neighbors renovating (I had my share of this one during the pandemic), or traffic noises from the street. By using better headsets and noise suppression these can be improved and even solved.
The network is the bigger headache though. Many of your agents are likely to be non-technical in nature. How do they configure their home network? Which ISP are they using and with which communication bundle? How are they even connected to the network – via wifi or ethernet? How far are they from the wifi access point? Who else is using their home network and how? How is their network configured?
The answers to the questions above are going to affect the network quality and resulting audibility of their calls.
Since we can’t control their network, we at least want to understand it properly to be able to make intelligent decisions, such as routing calls to agents that have better networks and environments or to assist our agents in improving their network and environment.
Assessing a WFH call center agent’s environment
They say that knowing is half the battle. In order to solve a call quality problem you should start from understanding what is causing it, and that comes from understanding the network and environment of your agent.
There’s no specific, single solution or problem here, which is why the process usually takes a lot of back and forth interactions between the agent and the IT/support helping them out remotely.
What are the things that you’d like and need answers to?
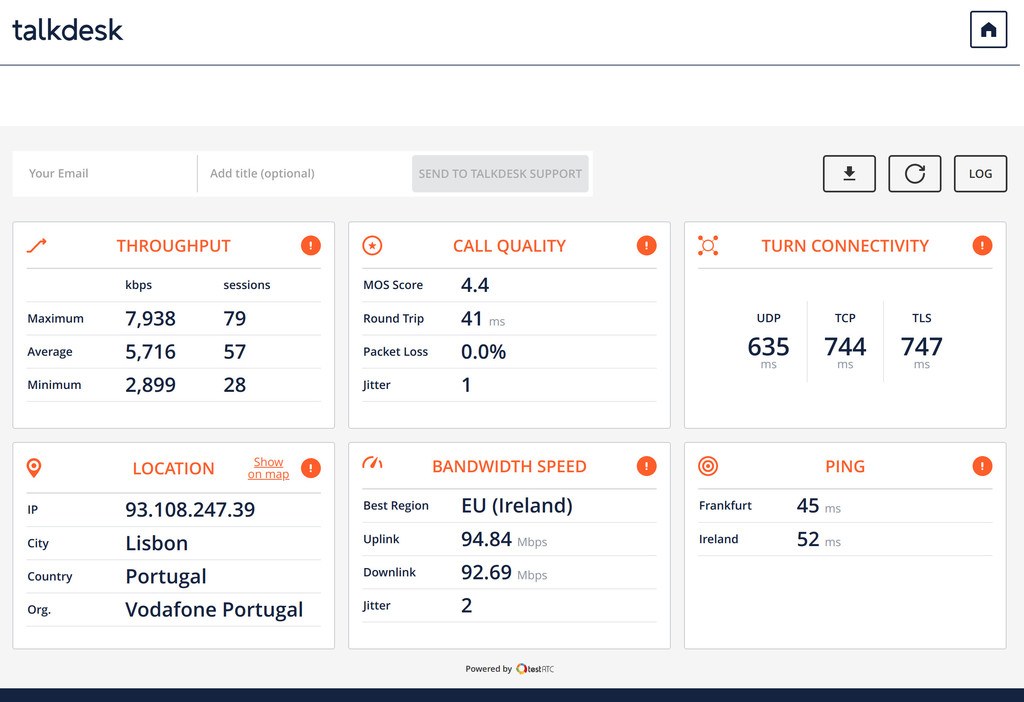
- What machine, operating system and browser is the agent using?
- Are they using a headset? Is it a bluetooth one? Is it the one provided to them for this purpose?
- Where is the agent located exactly? What ISP are they connected through?
- Is the agent using a VPN? Are they behind a firewall? Has someone configured the agent’s DNS servers inappropriately? (you’ll be surprised)
- Are their calls directed to the correct call center in a region nearby?
- Can their calls flow over UDP or are they forced over TCP?
- Are all of your applications needed by the agent available and reachable?
- What does the agent’s network look like? Is it fiber? ADSL? Something else? Is their uplink accommodating enough for calling services?
- How much VoIP traffic can their network handle?
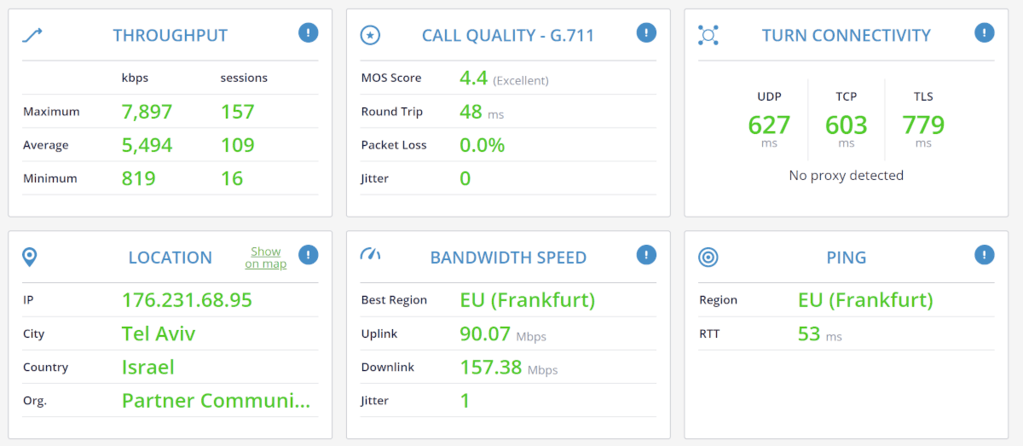
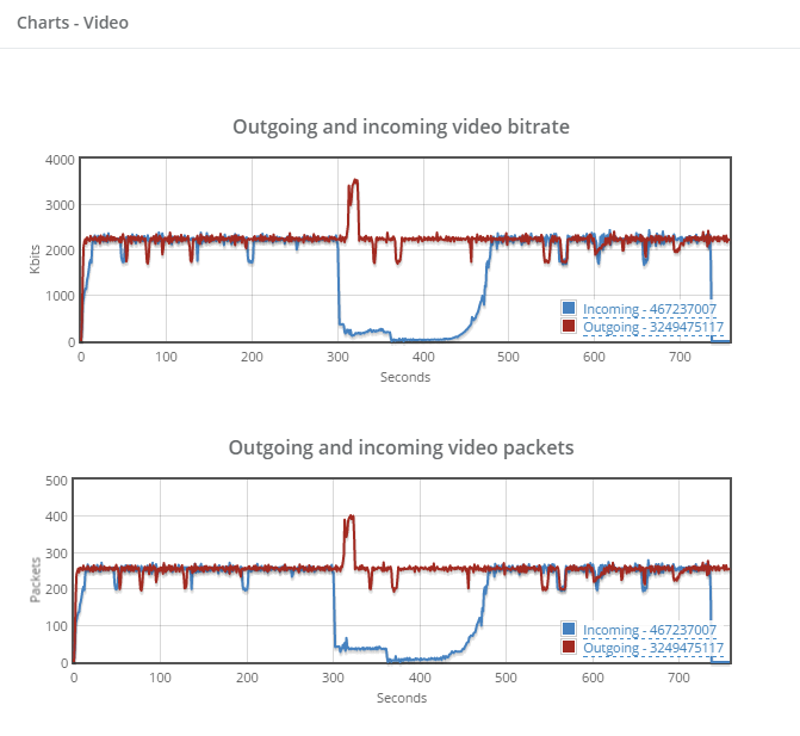
- When the agent connects to the PBX, what call quality do we measure?
- Is his network clean or noisy with packet losses and jitter?
- What’s the latency like?
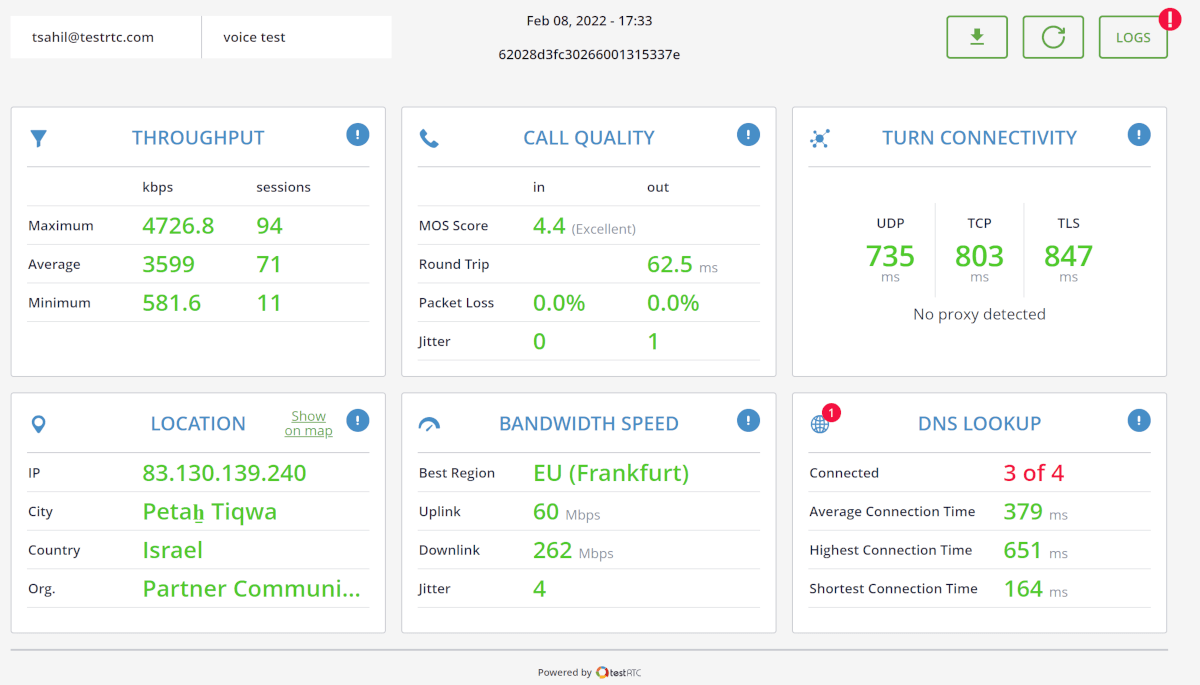
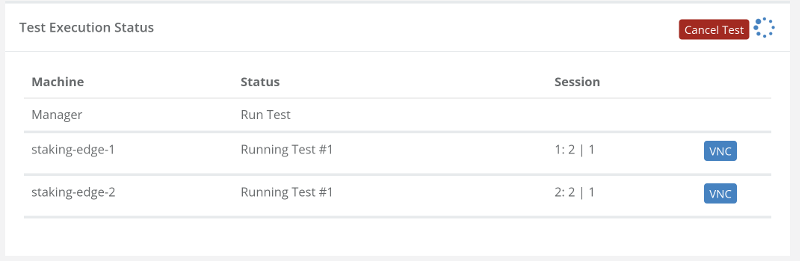
Getting answers to these questions quickly and accurately reduces the handling time of such issues. This is what our clients use our qualityRTC product for – to get the data they need as fast as possible to help them resolve issues sooner.
What’s your workflow?
Each call center has its own nuances – different infrastructure to test and different locations.
You have your own workflow and support process to tackle issues. Do you empower agents with self service, or keep close tabs on when and how network tests are conducted?
Some would rather have agents test their network daily at the beginning of the shift, while others want that to take place only when issues arise.
Large call centers usually need access to the data for BI purposes. Others want to map all their call center agents’ status once in a while – just to understand where they stand.
We’ve built qualityRTC with the help of the biggest call center providers out there, so we’ve got you covered no matter your workflow. qualityRTC is flexible to the level you’ll need to help you in reducing your support strains of WFH agents and get you focused on what really matters – your customers.
If you want to really up your game in WebRTC diagnostics – for either voice or video scenarios – with Twilio, some other CPaaS vendor or with your own infrastructure – let us know. We can help using our qualityRTC network testing solution.
")