Monitoring WebRTC apps just got a lot more powerful
As we head into 2019, I noticed that we haven’t published much around here. We doubled down on helping our customers (and doing some case studies with them) and on polishing our service.
In the recent round of updates, we added 3 very powerful capabilities to testRTC that can be used in both monitoring and testing, but make a lot of sense for our monitoring customers. How do I know that? Because the requests for these features came from our customers.
Here’s what got added in this round:
1. HAR files support
HAR stands for HTTP Archive. It is a file format that browsers and certain viewer apps support. When your web application gets loaded by a browser, all network activity gets logged by the browser and can be collected by a HAR file that can later be retrieved and viewed.
Our focus has always been WebRTC, so collecting network traffic information that isn’t directly WebRTC wasn’t on our minds. This changed once customers approached us asking for assistance with sporadic failures that were hard to reproduce and hard to debug.
In one case, a customer knew there’s a 502 failure due to the failure screenshot we generate, but it wasn’t that easy to know which of his servers and services was the one causing it. Since the failure is sporadic and isn’t consistent, he couldn’t get to the bottom of it. By using the HAR files we can collect in his monitor, the moment this happens again, he will have all the network traces for that 502, making it easier to catch.
Here’s how to enable it on your tests/monitors:
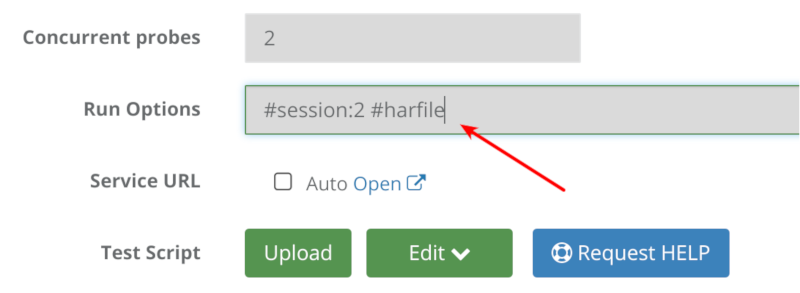
Go to the test editor, and add to the run options the term #har-file
Once there and the test/monitor runs next, it will create a new file that can be found under the Logs tab of the test results for each probe:
We don’t handle visualization for HAR files for the moment, but you can download the file and place it on a visual tool.
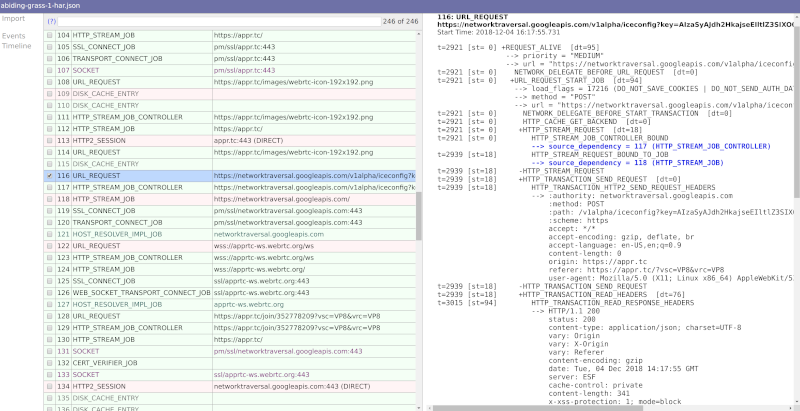
I use netlog-viewer.
Here’s what I got for appr.tc:
2. Retry mechanism
There are times when tests just fail with no good reason. This is doubly true for automating web UI, where minor time differences may cause problems or when user behavior is just different than an automated machine. A good example is a person who couldn’t login – usually, he will simply retry.
When running a monitor, you don’t want these nagging failures to bog you down. What you are most interested in isn’t bug squashing (at least not everyone) it is uptime and quality of service. Towards that goal, we’ve added another run option – #try
If you add this run option to your monitor, with a number next to it, that monitor will retry the test a few more times before reporting a failure. #try:3 for example, will retry twice the same script before reporting a failure.
What you’ll get in your monitor might be something similar to this:

The test reports a success, and the reason indicates a few times where it got retried.
3. Scoring of monitor runs
We’ve started to add a scoring system to our tests. This feature is still open only to select customers (want to join in on the fun? Contact us)
This scoring system places a test based on its media metrics collected on a scale of 0-10. We decided not to go for the traditional MOS scoring of 1-5 because of various reasons:
- MOS scoring is usually done for voice, and we want to score video
- We score the whole tests and not only a single channel
- MOS is rather subjective, and while we are too, we didn’t want to get into the conversation of “is 3.2 a good result or a bad result?”
The idea behind our scores is not to look at the value as good or bad (we can’t tell either) but rather look at the difference between the value across probes or across runs.
Two examples of where it is useful:
- You want to run a large stress test. Baseline it with 1-2 probes. See the score value. Now run with 100 or 1000 probes. Check the score value. Did it drop?
- You are running a monitor. Did today’s runs fair better than yesterday’s runs? Worse? The same?
What we did in this release was add the score value to the webhook. This means you can now run your monitors and collect the media quality scores we create and then trendline them in your own monitoring service – splunk, elastic search, datadog, whatever.
Here’s how the webhook looks like now:
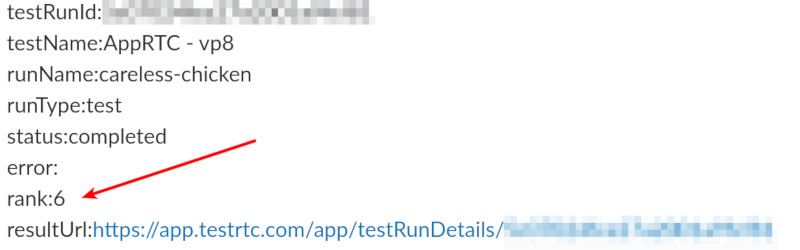
The rank field in the webhook indicates the media score of this session. In this case, it is an AppRTC test that was forced to run on simulated 3G and poor 4G networks for the users.
–
As with any release, a lot more got squeezed into the release. These are just the ones I wanted to share here this time.
If you are interested in a monitoring service that provides predictable synthetics WebRTC clients to run against your service, checking for uptime and quality – check us out.