Executing a WebRTC test that scales
There’s a growing trend from the companies that come to testRTC in recent months, and it has to do with the focus of what they are looking for.
Most are less interested in how testRTC can be used for functional testing – things like coverage of scenarios and finding edge cases and automating tests for them. What people are interested now when they want to run a WebRTC test scenario is how to scale it.
Customers typically try to take stress in WebRTC tests in two slightly different vectors: they either focus on testing how their WebRTC service can handle multiple sessions in parallel or they focus on testing how their WebRTC service can increase the number of users in a single session.
Let’s review what’s the meaning of each of these alternatives.
#1 – WebRTC test that scales to a large number of sessions
I decided to put things on a simple graph. The X axis denotes the number of sessions we’re going to focus on while the Y axis is all about the number of users in a single session.
In this case, where we want to test WebRTC for a large number of sessions, we will have this focus:
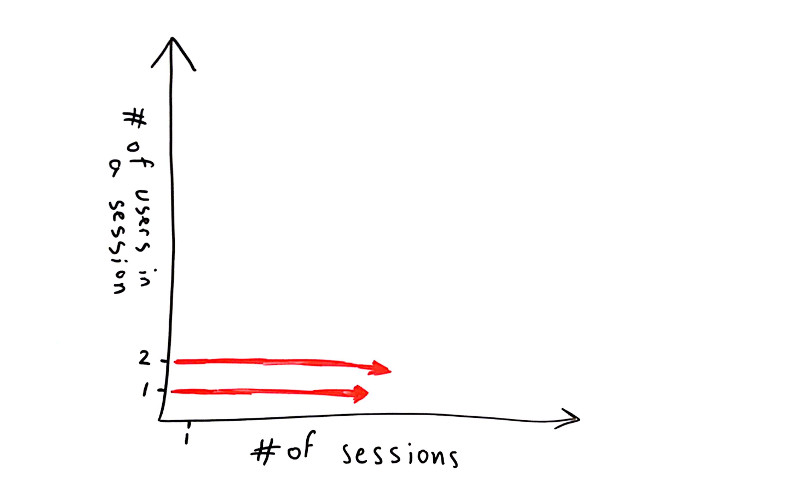
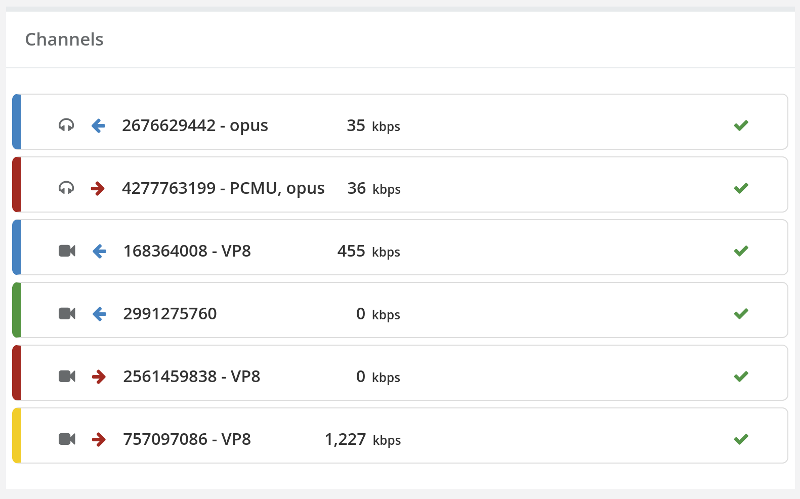
So we have a WebRTC service to test. It has a single user in a session (a contact center agent receiving calls from PSTN for example) or two users in a session (one person talking to another across browsers).
In such a case, vendors are usually concerned about stressing their servers – checking if they can fit their intended capacity.
When this is done, there are three different things that can be tested for scale:
- The signaling server
- How well does it behave while increasing capacity? How is its connection to the databse? Does it slow down as connections accumulate? Does it leak memory?
- Usually, stress testing a signaling server is better done with other tools. Ones that have a lower cost per connection than testRTC and don’t really require a full browser per connection
- That said, oftentimes, you may as well want to throw in a few “real” users using testRTC on top of a tool that loads your signaling connections separately – just to make sure there’s nothing that kills your service when media is added into the mix on top of the signaling
- You also need to think about the third component below – how do you test your TURN server?
- The media server
- These crop into 1:1 tests when there’s a need to record the session or to enforce a given route. I’ve seen many of these recently, mainly in the healthcare and education markets
- For single users, this usually means the gateway that connects the user to other networks is what we want to test, and there it will usually include a media server of sorts for media transcoding
- In such a case, there’s no getting away from the fact that scale is in the low 10’s or 100’s of browsers and real ones are needed. It is also where we see a lot of interest in testRTC and its capabilities
- The TURN server
- Anywhere between 5-20% of the calls will end up being relayed via a TURN server – and there’s nothing you can do about it
- If you put up your own TURN servers – how confident are you in your setup and its ability to scale nicely as your service grows?
- One way to find out is to place real browsers in front of your service, but doing so in a way that forces the browsers to negotiate via TURN. This can be acheived by changing the configuration of your client, filtering ICE candidates and doing SDP munging. A better way would be to enforce network rules on the machine running the browser and actually test your service in different network conditions
- And yes. testRTC allows you to do just that
#2 – WebRTC test that accommodates a large group of users in a single session
The other type of focus use cases we see a lot from our customers are those that want to answer the question “how many users can I cram into a single session without considerably degrading the quality?”
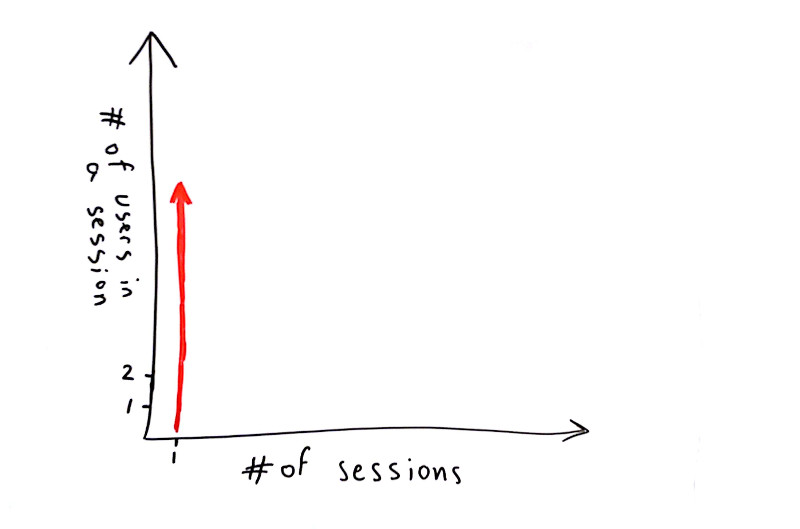
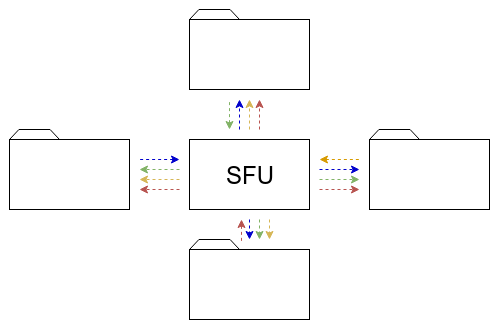
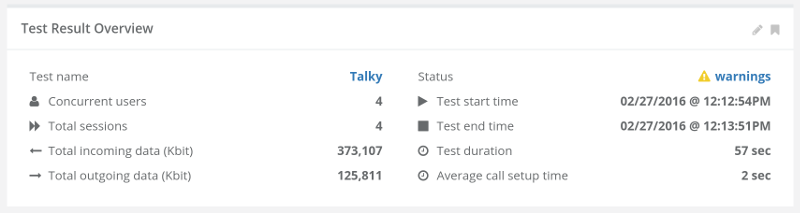
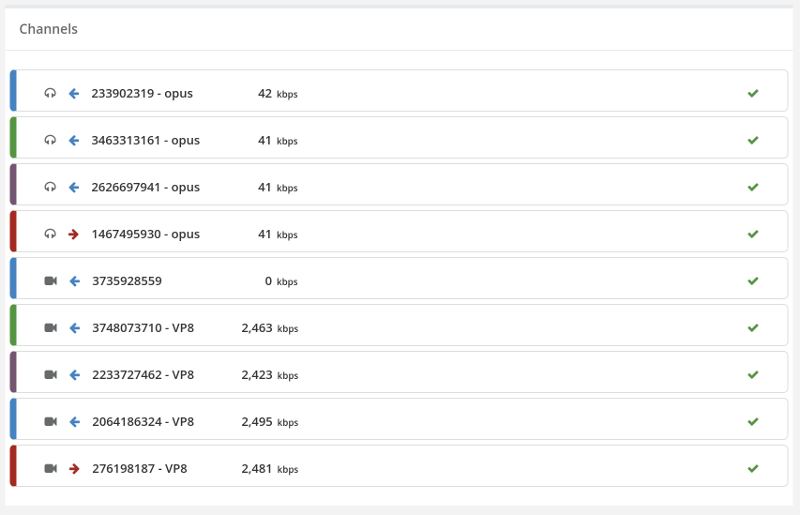
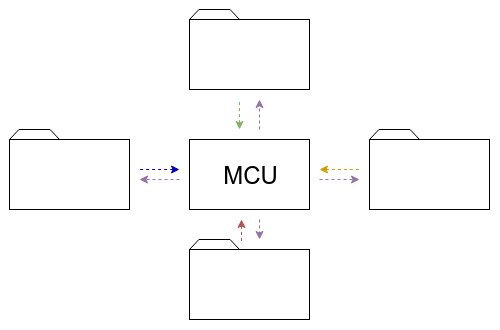
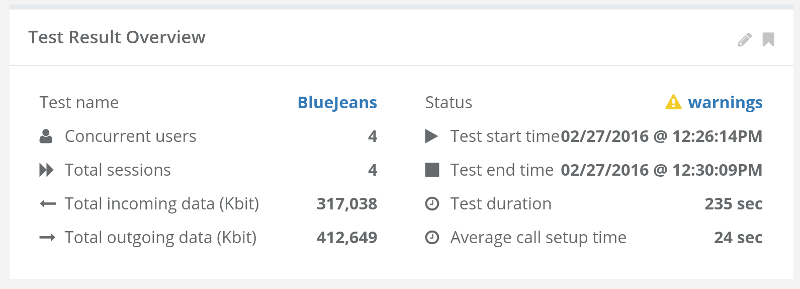
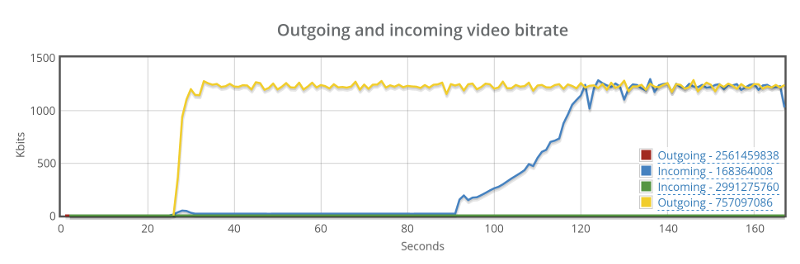
Many look for doing such tests at around 10-20 concurrent browsers, either in MCU or SFU models (see this post on the differences between the multiparty WebRTC technologies).
What happens next is usually a single session where browsers are added one on top of the other to check for scale. Here, the main purpose of a test is validating the media server and not much else.
The scenario is rather simple:
- Try 1:1. Record the results
- Go for 4 users. Record the results
- Expand to 10 users. Record the results
- Rinse and repeat
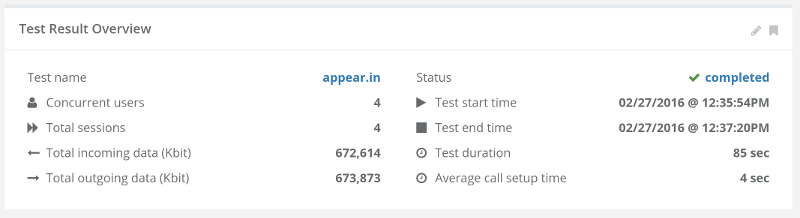
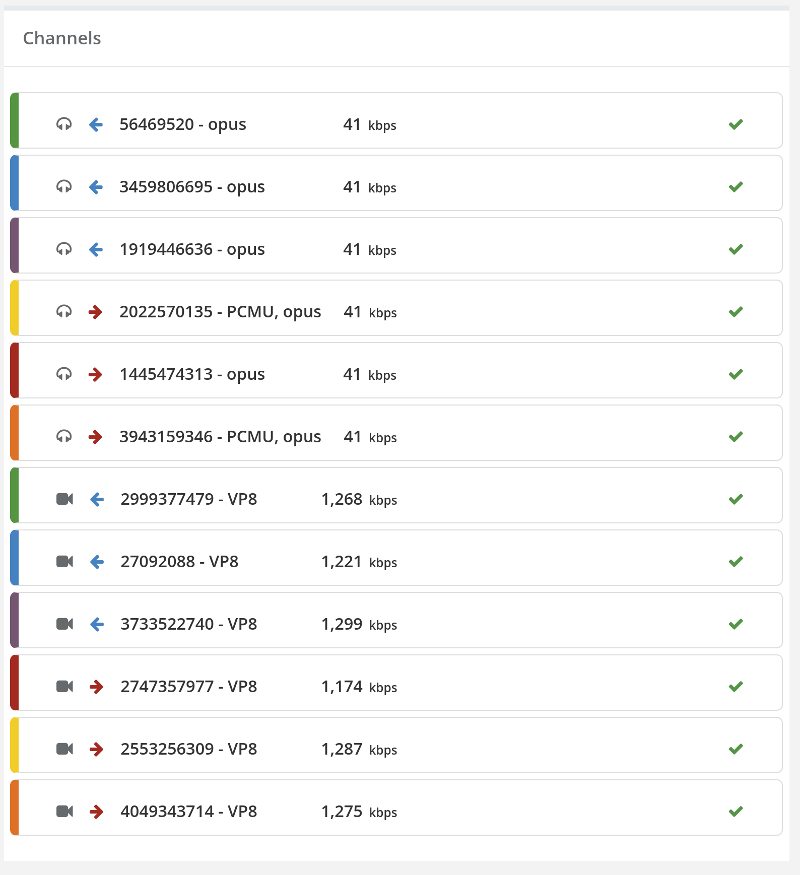
Now go back to the recorded results and see if the media got degraded:
- Was latency introduced?
- Do we see more packet losses?
- Does bitrates go down the more browsers we add?
- Is the bitrate stable or fluctuating all over the chart?
- Is the degradation linear or exponential?
These types of questions are indicators to problems in the WebRTC product’s infrastructure (be it network connections, CPU, storage or software).
#3 – Test WebRTC at scale
And then you can try to accommodate for both these needs. And you should – scale the size of the sessions at the same time that you scale the number of sessions.
Here what we’re trying to do is everything at the same time.
We want to be able to place multiple users in the same session but spread our browsers across sessions.
How about running 100 browsers, split across 10 different sessions, where each session accommodates for 10 browsers? This is where our customers are headed next after they tested their WebRTC multiparty service for a single session capacity.
Why is WebRTC test scaling so hard?
When you scale test WebRTC infrastructure, you end up needing lots of bandwidth and processing power. Remember that each user is a full browser (why that is necessary see here). Running 2 or 4 of these may be simple, but running 20 or more becomes quite a challenge:
- You can no longer place them all in a single machine, so you need to start distributing them – across machines, across data centers
- You need to take care of both downlink and uplink network speeds – this isn’t easy to acheive at scale
- You need to synchronize across your small army of browsers so they hit the server at roughly the right time for it all to work
- Oh – and you need the WebRTC test environment to be stable, so that when issues occur, it will more often than not be due to an issue in the tested product and not in your test environment itself
testRTC, users and sessions
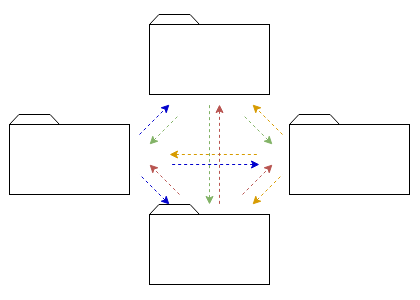
There are many ways to do multiple users in a single session:
- All join the same URL or room, given the same level of access
- A chair hosting a large conference, where control and access is assymetric
- A broadcaster and a large number of viewers
- A few people in a discussion with a large number of viewers
- …
Each of these scales differently and requires a slightly different treatment.
What we did at testRTC was introduce the notion of #session into the mix. When you indicate #session, the test will automatically wrap itself around that notion – splitting the number of concurrent users you want into sessions at the size you state by #session.
Want to see it in action? Check our our latest tutorial videos on how to scale WebRTC tests in testRTC, by using the notion of a session: