
Call it WebRTC active monitoring or WebRTC synthetic monitoring, the concept is rather simple. What you are trying to do is run a scenario from real browsers the same way a user would. Why? So you can see (=track and monitor) your WebRTC application the way your customers do.
–
You know pingdom? It is a service that pings your website every couple of seconds. If it fails to get a response – you receive an email that your website is down. A simple and straightforward solution. There are many similar services out there and they work beautifully. If all you’re after is to answer the question “is my website still up?”
This, though is different than asking the question “is my website working properly?”
How do you go about monitoring a website for that? You dig one or two levels deeper, specifically, by putting on probes that load your webpages and look for indication that these pages are fresh and not erroneous. Why? Because a ping test of a website can be happy with this kind of a result:
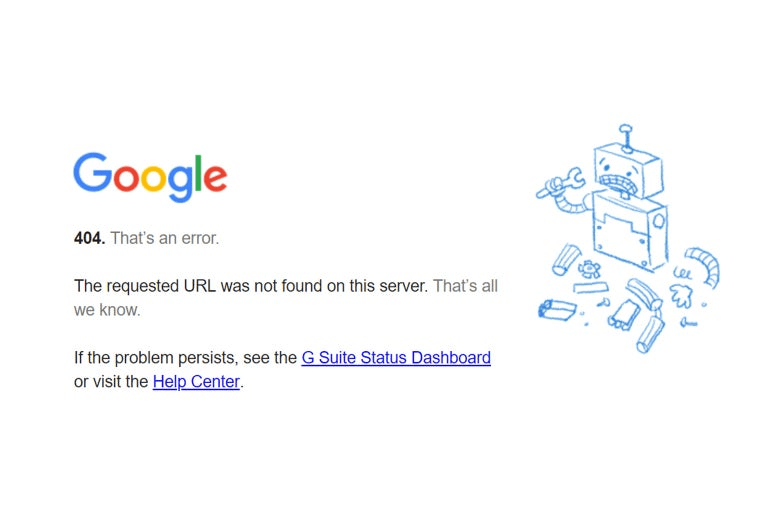
That’s Google Calendar being down a few weeks back. I am not sure that a ping test would notice that, as a page does load.
The path to synthetic/active monitoring
What would an IT person do? Add more metrics that he can track. CPU use, memory use, network traffic. And then add more metrics from the application: page views, open sessions, etc.
These metrics are prone to two problems:
- Seasonality changes their behavior. Think weekend or holiday traffic versus regular days, or opening hours versus night time
- The lights might be on but there’s nobody home. All looks fine, but somehow a user is unable to login or get connected to a certain service due to breakage in the connection of two internal systems. Since monitoring is done on low level metrics, such cases might be missed
The next step for our IT person would be to have a probe act like a user to going through the system to understand its behavior. These probes conduct synthetic monitoring, where they act like real users going through the system.
The same applies to WebRTC applications as well.
8 benefits of active monitoring in WebRTC
Call it WebRTC active monitoring or WebRTC synthetic monitoring, the concept is rather simple. What you are trying to do is run a scenario from real browsers the same way a user would. Why? So you can see (=track and monitor) your WebRTC application the way your customers do. And once you automate it and run it frequently, you can gain insights and understanding that you just can’t get in any other way.
Here are 8 benefits that got customers like Vidyo to use testRTC for monitoring their WebRTC cloud deployment:
#1 – Predictability and Objectivity

When you run an active monitor you are in control. You know where the probes are coming from, what is the performance of the machines they use offer, and what their network conditions are. And if you don’t, then running that active monitor in the same scenario a couple of times will create the baseline you need.
With that information, you can now run the scenario as an active monitor, and if all goes well the results will be consistent. The moment something changes – there’s a pretty high level of confidence that something changed in your WebRTC deployment. That’s predictability.
The fact that the metrics collected and analyzed results are based on machine automation, you also gain objectivity. While it will be hard to say how bad a jitte value of 120 is versus 100, it will be easy to say that if you had a jitter value of 100 for a few months and now that has changed to 120 in the monitor you are running, then things changed for the worse, and it would be wise to check why.
#2 – End-to-End

When we deploy a monitor with a new client of ours at testRTC there’s almost always a learning period of a month or two. At that time, we need to assist our client to fine tune and tweak the script written for the monitor.
Common things we need to do is slow down button clicking or add retries in certain strategic places (like login procedures). Why? Because production WebRTC services sometimes receive 502 when people try to login, connect or start sessions. Real users would simply refresh the page by clicking F5 or retry clicking a button.
In some cases, our clients would go about hunting these bugs and fix them. In others, we’d build these retry mechanisms into the script used by the monitor.
The thing is though, that when a WebRTC session fails, it can fail a lot before it even started. Or it can work nicely, but screen sharing fails. Or screen sharing will work but PSTN dial-in won’t. Being able to define the most important WebRTC scenarios and synthetically monitor for them gives you an end-to-end solution.
#3 – Be the first to know

You need to be the first to know when there is an issue. That issue can be with the login, directory service, session initialization, media quality or any other problem that might arise.
If you are operating a contact center, then calls take place at certain times of the day (office hours). Understanding potential failures before they happen simply by running a monitor prior to a Monday morning shift starting the day would give you more time to resolve issues.
If you have millions of calls taking place a day on your system, then this might not be an issue for you – or more likely, your users would complain at the same time your service monitoring will notice a failure. In such a case, other reasons such as predictability would make more sense to using synthetic monitoring. This is doubly so since using predictable probes that create synthetic sessions should result consistent outcomes, as opposed to real users where you lack any control over their machine, location and network.
#4 – Simplicity

There’s something to be said about simple approaches for complex problems.
When users can’t connect to your service, do you know why that is? If they complain about quality, is it because of their device, network connection or your service? How do you even go about analyzing this?
WebRTC synthetic monitoring reduces a lot of the variables and brings predictability with it into the process. What you end up collecting and how you serve that to the IT person in charge is also quite important – there are so many metrics and parameters to look at with WebRTC that many don’t find their way around.
What we’re razor focused in testRTC is in making the analysis process as simple as possible to our clients. Letting them glean the insights they need with the least amount of effort on their part. Our upcoming release goes in that trend and is already being trialed by a few of our clients.
#5 – Debuggability

The monitor failed or alerted at an issue. Great. Now what? How do you make that alert an actionable one?
With passive monitoring of live users, there’s very little you can do in a lot of cases. Quality is a subjective thing that is affected quite a lot by the user’s own device and network. Move a meter or two farther away from your current position while in a call, and your Wifi connection might become unusable. In my house, using Wifi in the bedroom is quite the challenge. The living room and my home office? They’re guaranteed to give high network quality. At least up to the carrier. My desktop has its good days and bad days, depending on the number of Chrome tabs opened and the number of days since the last reboot.
If you run a synthetic monitor for WebRTC, then there are quite a few things at your disposal. Here are some that we’ve implemented in testRTC for our clients:
- Collect all possible data, so developers can look at logs and figure out the issues. This includes WebRTC metrics, browser console logs, network events log, browser performance data and screenshots
- Visualize the scenario and the metrics collected, keeping it simple at first glace with high level graphs and aggregations while enabling drill down to the minute details
- Automate threshold on metrics, to make sure tests warn or fail on certain use cases and conditions that are suitable for you
- Grab a screenshot at the time of failure, so you can see the moment the scenario fails
- Execute the scenario again, so you can see the failure (since the scenario and probes are predictable, there’s a high likelihood the failure will occur again)
- Join a running synthetic session via VNC, so you can see for yourself how the session progresses
#6 – No instrumentation

Synthetic monitoring requires no instrumentation of your service.
Since you end up using real browsers, running real scenarios, the only thing you’ll probably need is create certain users for running the monitor and that’s about it.
There’s no code you’ll need to inject into your service. No js file to include. No SDK to compile into your app.
That means it is faster to deploy to production than alternatives and the potential effect it has on your service due to the addition of external code is non-existent, since you’ve changed nothing in the code.
#7 – Privacy

A synthetic monitor collects synthetic metrics. It doesn’t sit on your live users, so there’s no live user data collection taking place. There’s also no real indication of the size of your deployment, the trajectory and growth of your service or anything similar associated with it.
We’ve seen reluctance of clients to share such data with cloud based services. These mostly stem from legal issues such as where the data gets collected and stored, but also from a business perspective of having a third party trusted with the day to day communications that takes place. In many cases, companies are happier having this part of the operation take place in-house.
With an active monitor, the only data collected and analyzed is the data generated by the browser of the active monitor itself and no one else. The users used by the active monitor are dummy users created for that purpose only.
#8 – Fixed investment

Talking about predictability… as your service grows, a WebRTC active monitor act in the same manner. This means your investment in running the monitor won’t be changing either. This is never the case with a passive monitor, where pricing is based on the size of the user base as well as the amount of traffic.
That means you can budget and plan ahead for longer periods of time at relatively low investment.
When will you need to grow your investment? When you want to deepen your analysis. This is done by deploying more monitors (to run from more geographic locations or to hit different data centers of your service), increasing the frequency of the monitors (to get alerted on issues earlier) or when you beef up monitors (by adding more probes to test larger video group calls for example).
testRTC’s active monitoring
If you are in need of better visibility of your WebRTC application, then by all means – explore passive monitoring and deploy it. But also check how active monitoring can improve your day-to-day operations and in the end, improve uptime and media quality for your users.
We’re here to help, so contact us for a demo.