How do WebRTC Media Servers Behave on Packet Loss?
Differently from each other.
Whenever I see people comparing WebRTC media servers, they tend to focus on scale:
– How many sessions can you cram in parallel?
– How many streams can you serve from a single machine?
– How much bitrate can you pump out?
All of these are very important questions – they end up in your sizing calculation that then go into your pricing model for your service. Oh, and we did cover this a bit here when talking about handling WebRTC browsers synchronization at scale.
Now that our new version is taking shape (still in staging, so if you want access – ping us), it is time to play a bit with a few new toys we’ve added for our beloved community of sadists (you may know them as test engineers, but the good ones are sadists – they like inflicting pain upon digital products and services).
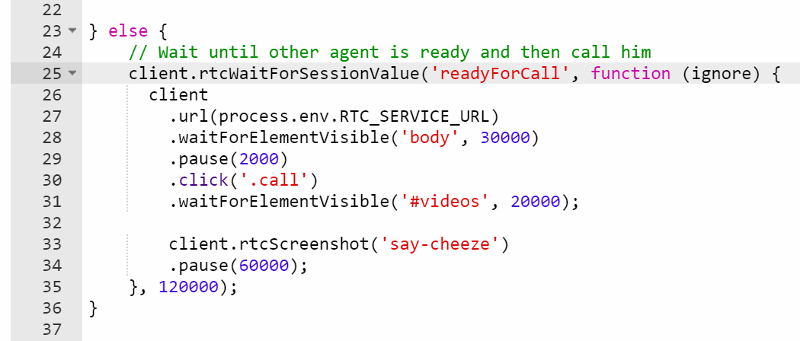
What I am talking about here is a combination of two script commands we have:
- rtcEvent() – place a vertical event in the graphs
- rtcSetNetworkProfile() – change network profiles in runtime
You’ll see how it looks in a second.
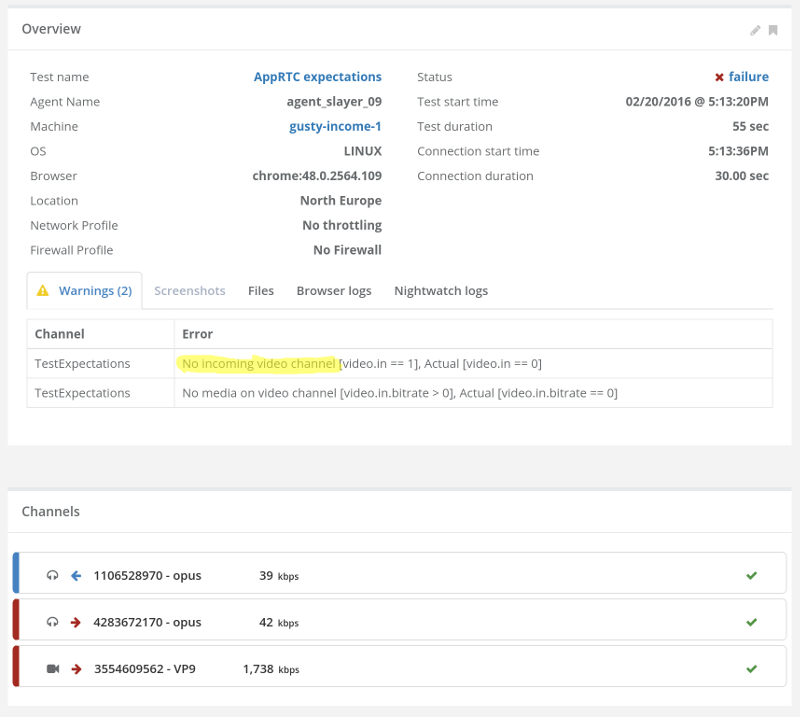
What Packet Loss Does?
Packet loss is bad.
You don’t control it. And it can happen at any time. Come and go as it pleases.
The moment you have packet loss, there will be some degradation in the quality of the media. Lost packets means lost data. Means can’t playback something. It might be minor. It might be important.
Next thing that happens? WebRTC (or most other VoIP products for that matter) will start lowering bitrates. Why? Because it assumes there’s congestion on the network, and it is trying to play nice with everyone.
But what happens once that packet loss is gone? Does things go back to normal? And if they do, then how fast will that happen?
My Experiment
I decided to devise a simple enough experiment to get some answers here. I chose the following steps:
- Connect to a service
- Run for a full minute
- Set packet loss to 10% for a full minute
- Go back to normal – no packet loss
- Wait two minutes

That’s it. What I am interested in is less of what happens during the second minute, but more what happens in the last two minutes, and how that is different than what we have in the first minute of the session.
In general, I decided to place 5 users in the same session, to get that media server working a bit. And I also decided to focus on the SFU kind.
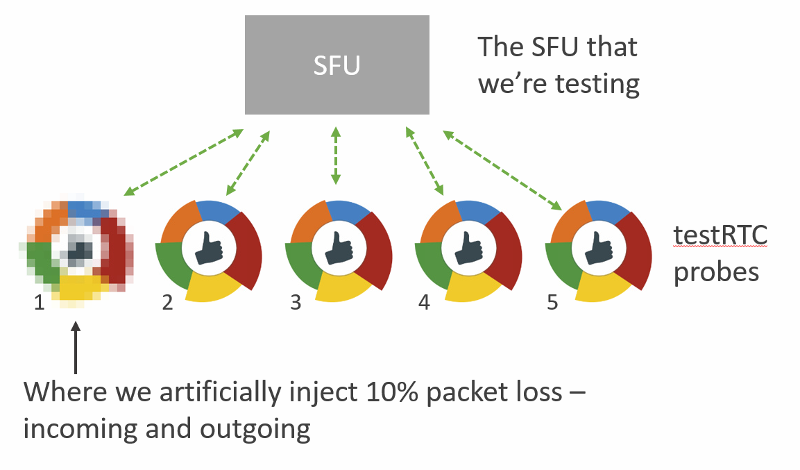
The services I tinkered with are:
- AppRTC, just as a baseline for this exercise
- Janus, an open source media framework, that can act as an SFU
- Jitsi Videobridge, an open source SFU
- mediasoup, a relatively new open source SFU
- SwitchRTC, a commercial SFU
- appear.in, a service that recently added its own self-developed SFU (in beta at the moment)
If you are looking for Kurento or other SFUs – they weren’t included not because I didn’t want to, but because there was no readily available installation out there that I could just use.
I’ll be happy to add more SFUs to the comparison, so give us a shout out if you want to run such an analysis.
Let the fun begin.
AppRTC – My Favorite Baseline
For our baseline, I decide to use AppRTC.
This time, I had to use only 2 browsers, as AppRTC doesn’t support any group calling capabilities.
What it does do is offer the vinyl WebRTC experience.
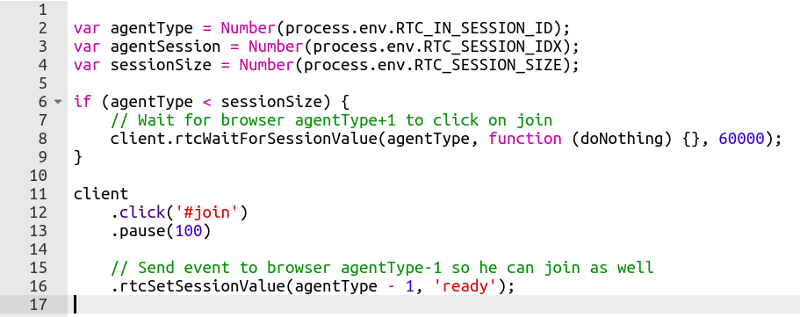
I started with writing a simple script to fit my needs:
var roomUrl = process.env.RTC_SERVICE_URL + "testRTC" + process.env.RTC_SESSION_IDX + '?vsc=VP8';
var agentType = Number(process.env.RTC_IN_SESSION_ID);
var recuperationTime = 60; // in seconds
client
.rtcInfo(roomUrl)
.rtcProgress('open ' + roomUrl)
.url(roomUrl)
.waitForElementVisible('body', 60000)
.pause(2000)
.click('#confirm-join-button')
.waitForElementVisible('#videos', 20000)
// Minute 1
.pause(recuperationTime * 500)
.rtcScreenshot('Phase 1')
.rtcProgress('Phase 1')
.pause(recuperationTime * 500);
// Minute 2
if (agentType === 1) {
client
.rtcEvent('10% Packet Loss start', 'global')
.rtcSetNetworkProfile('custom', 'packet loss', 10, 'both', 'both'); // 10% packet loss
}
client
.pause(recuperationTime * 500)
.rtcScreenshot('Phase 2')
.rtcProgress('Phase 2')
.pause(recuperationTime * 500)
if (agentType === 1) {
client
.rtcSetNetworkProfile('') // back to pristine network conditions
.rtcEvent('10% Packet Loss End', 'global');
}
// Minute 3-4
client
.pause(recuperationTime * 1000)
.rtcScreenshot('Phase 3')
.rtcProgress('Phase 3')
.pause(recuperationTime * 1000);
A few things to note here:
- All test scripts on this post can be found on our github account. Easiest way to use them is to import them into your testRTC account
- I decided to force VP8 here. VP9 is erratic a bit in its bitrate so I wanted to go for VP8 – hence the addition of ‘?vsc=VP8’ in the first line of this script (check out all of AppRTC’s parameters here)
- When the second minute is up, the first probe in each session will generate a global rtcEvent and set packet loss in both directions to 10% (look at lines 23-27)
- After an additional second is over, the first probe in each session will generate another global rtcEvent and remove all packet loss and network constraints that might have been used (look at lines 35-39)
Running that using testRTC yields these results once you drill into one of these sessions:
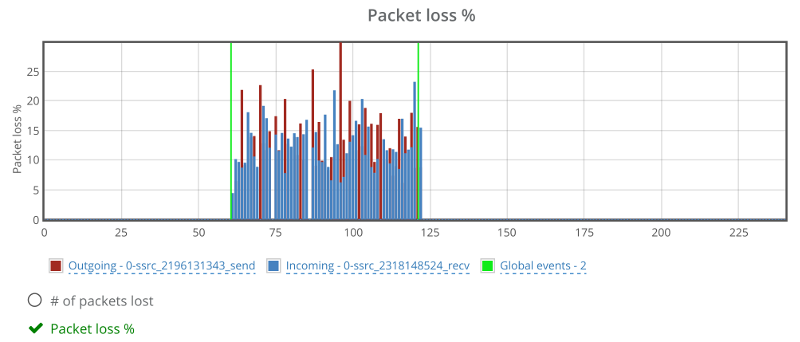
Above you see two things:
- The green vertical lines – these are the result of the rtcEvent() calls
- The blue and red bars, showing incoming and outgoing packet loss percentage, which averages at 10%
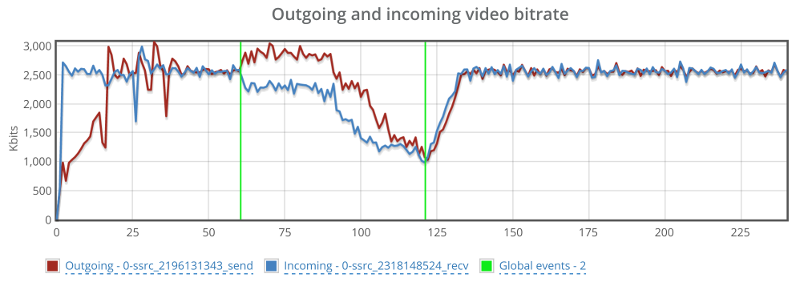
Above you see the video bitrate graph, with the two horizontal lines on it.
Notice how the outgoing bitrate tries going up in the beginning and then drops from 2.5mbps to 1mbps in 60 seconds?
The other thing that interest me is the time it takes for WebRTC/AppRTC to get back to 2.5mbps. And that’s somewhere in the range of 15-20 seconds.
Oh, and because I know you’ll be interested in this – also remember this screenshot of the video average delay we had:
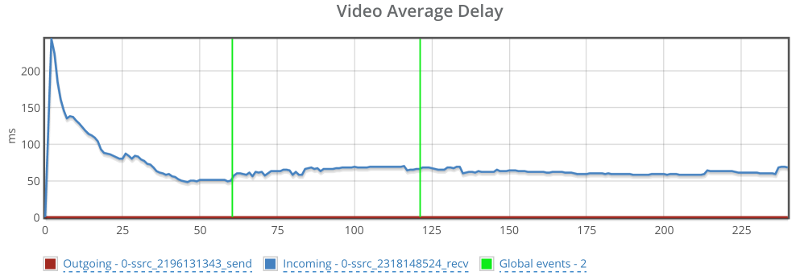
Before we move on to the media servers – remember that what I tried doing with AppRTC is provide a baseline. And the baseline here is “picture perfect”. I didn’t really expect any of the SFUs that I’ve used to be able to match AppRTC with its metrics.
Janus
Janus is an open source media server created and maintained by Meetecho.
They have an online demo running that supports a simple video room.
So we just hooked our script on top of that to get the results we needed. We aimed for 5 browsers in a single room – which will be the norm from now on in this article.
The Janus demo has somewhat of a single room, and I had to end up with a J3rry user in there, though he seemed harmless with no camera or bitrate in my session.
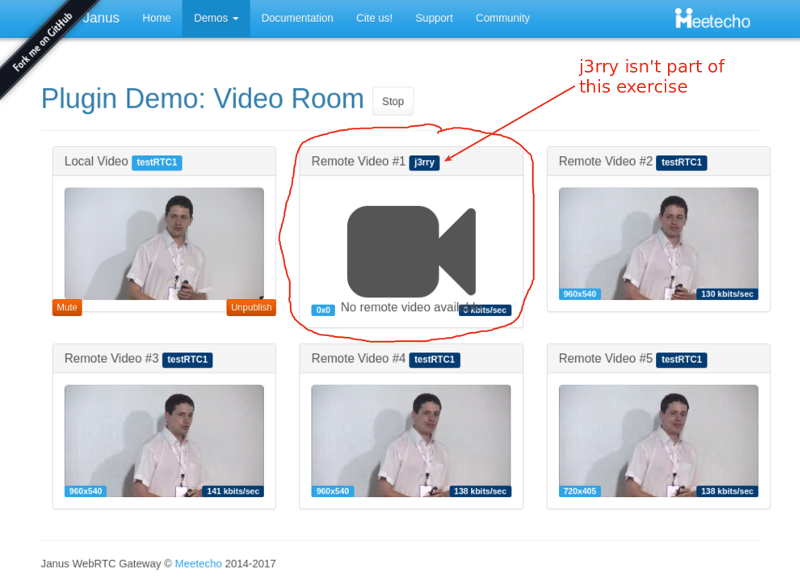
You can see above that the bitrates are rather low – around 140 kbps for each video stream coming into this room. And that’s even before I started adding packet loss.
During packet loss and after it, we “lost” two participants. Here’s a screenshot taken a minute after I stopped packet loss altogether:
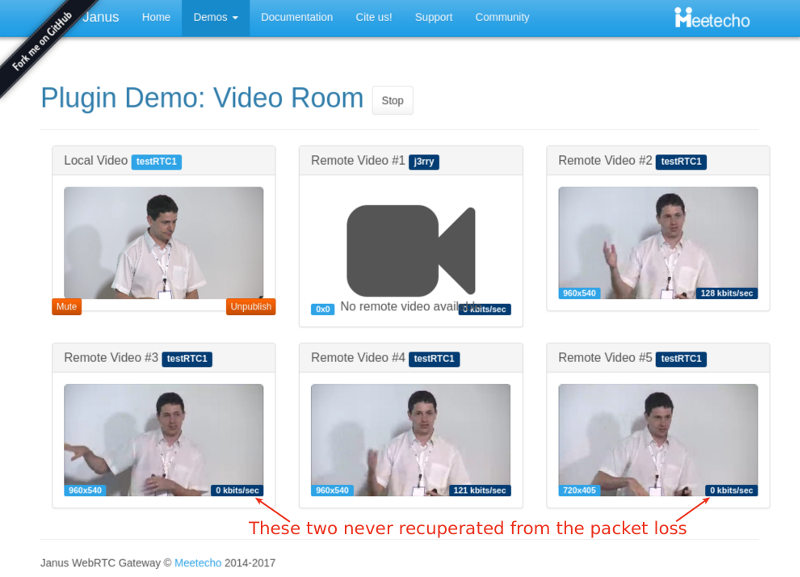
The graphs in testRTC show a grim picture:
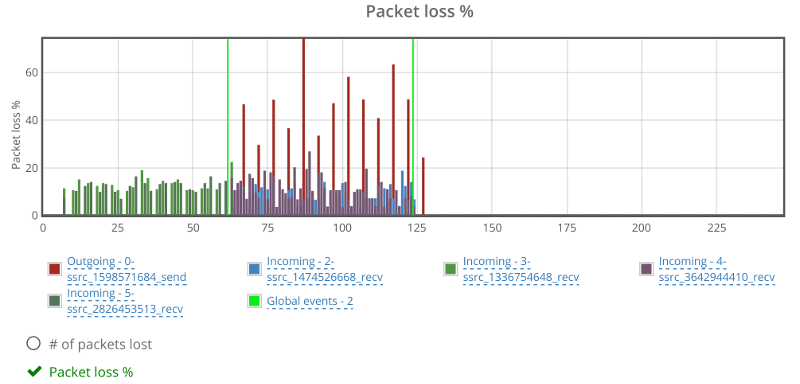
Janus reports packet losses at higher intervals than what WebRTC does, which is why we see the spikes on the outgoing reporting that go up to 50% and more. The weird thing is the two incoming channels that show around 10% of packet loss as well. Which is weird – more about this later.
Here’s how video bitrates look like for some of the streams (one outgoing and two incoming):
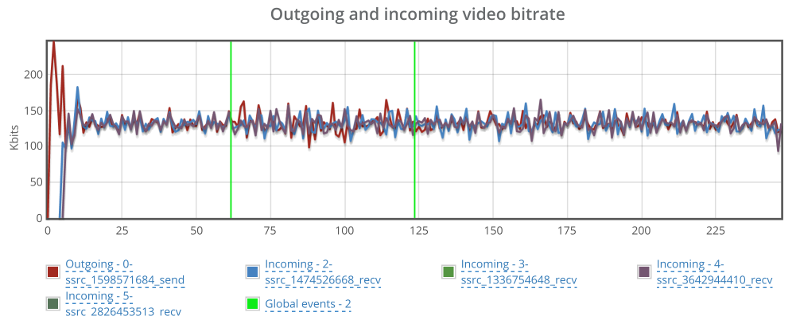
No change even though we have packet loss.
And here’s what happens in the two other incoming streams:
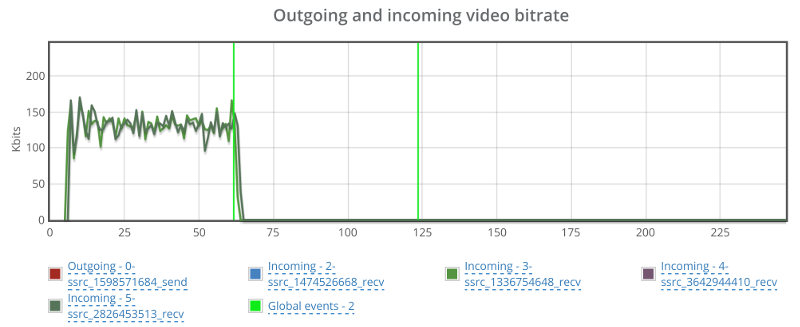
Apparently, these two incoming streams are the ones showing packet loss from the start. They somehow decided to drop to 0 the moment we cranked up the artificial packet loss from 0 to 10% – but never recuperated from it.
Looking at the average delay for the video…
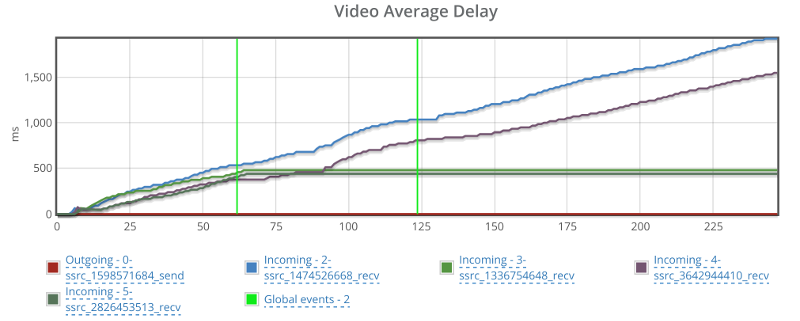
Things can’t be good, but seems like this has nothing to do with my packet loss shenanigans.
It might be Janus and it might just be the demo machine. If I could, I’d reboot it and start all over again.
Jitsi
For me the Jitsi Videobridge is where I go first to run demos and tests on an SFU with testRTC:
- It is out there
- It is easy to automate
- And I am a creature of habit…
To run our test here, we’ve directed 5 of our probes into a single room on the Jitsi meet online service/demo.
After a few attempts, I decided it would be better to disable simulcast, using this prefix to the URL: ‘#config.disableSimulcast=true’. I didn’t do it because simulcast is a bad thing, but because it made analyzing the results much harder for what I had in mind.
If we look at the packet loss graph, it will tell a similar story to what we’ve seen so far:
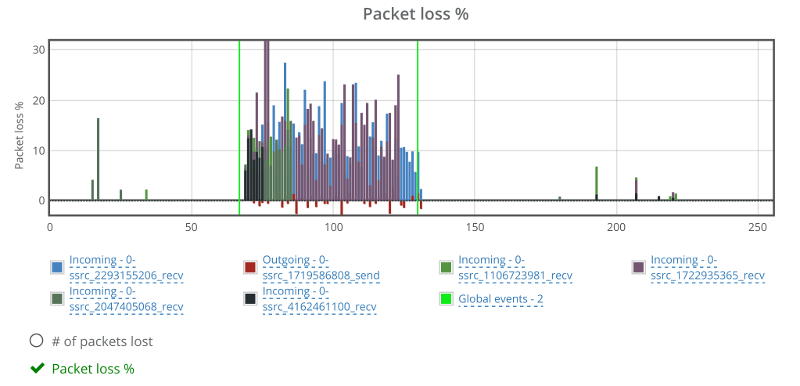
While there are some packet losses out of the one minute killzone I created, they are negligible (or at least sporadic). That negative values you see for packet losses in the red color? They are reports of the browser’s outgoing stream from the machine we induced packet loss on. This is most probably related to a Chrome bug (HT to Philipp Hancke).
I’ve split the video bitrate graphs here into two graphs – the outgoing one and the incoming ones since they tell two separate stories.
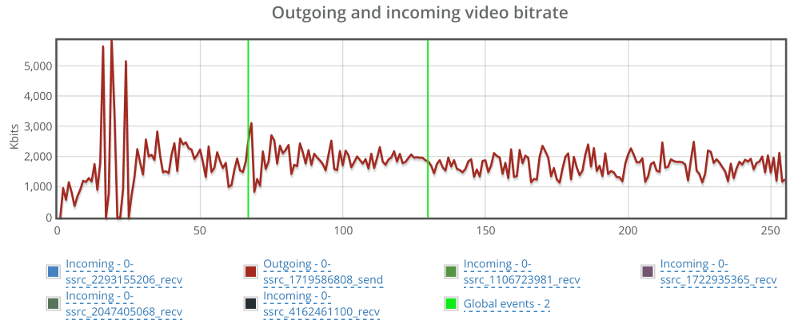
This one caught me by surprise – the outgoing bitrate shows no signs of a change due to packet loss. I wonder what Jitsi is doing (or not doing) to have packet loss ignored in such a way. So I decided to look at it from the receiving end of one of the other four browsers in the same session:
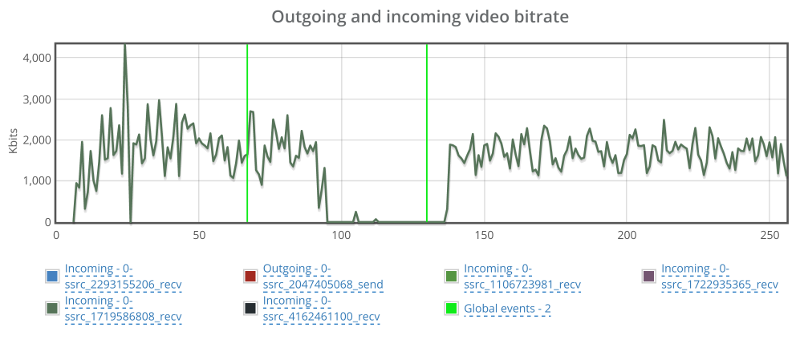
Bitrate drops to 0 for a duration of almost a full minute before coming back up.
Back to the browser with the trashed network, let’s see what happens to the incoming video streams:
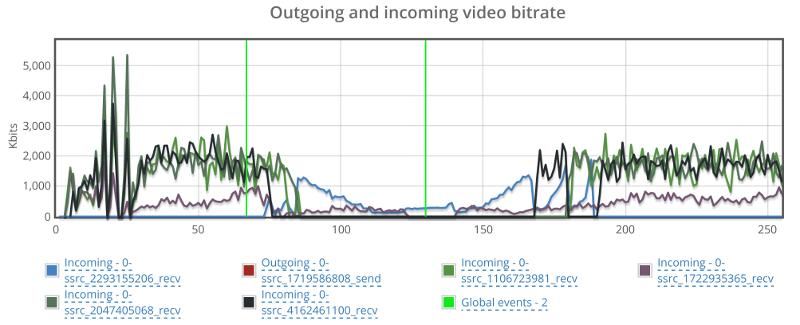
Things drop down from around 2mbps to almost 0 on all incoming channels, taking around 40-60 seconds to get back to normal.
One last glance before we move on – check out video average delay:
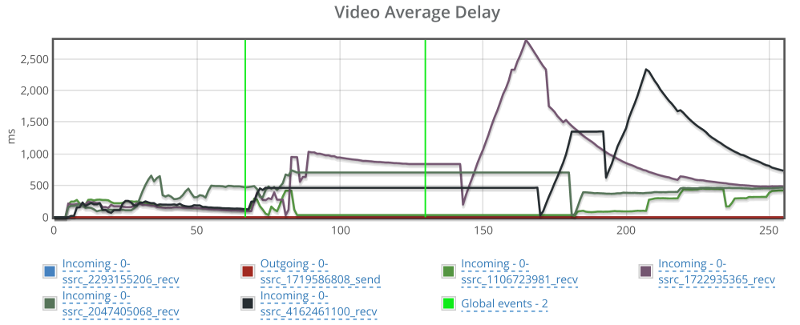
Jitsi had some hard time recuperating from that packet loss.
It should be noted that I’ve played around with Jitsi before their recent updates – especially the ones including adaptivity.
Mediasoup
mediasoup is a rather new player in the open source SFU space. It is built in C++ as a Node.js module. After a quick Twitter chat, Iñaki Baz Castillo was kind enough to configure it to my needs (specifically, allowing for more bandwidth on the online demo).
Starting as always with packet loss:
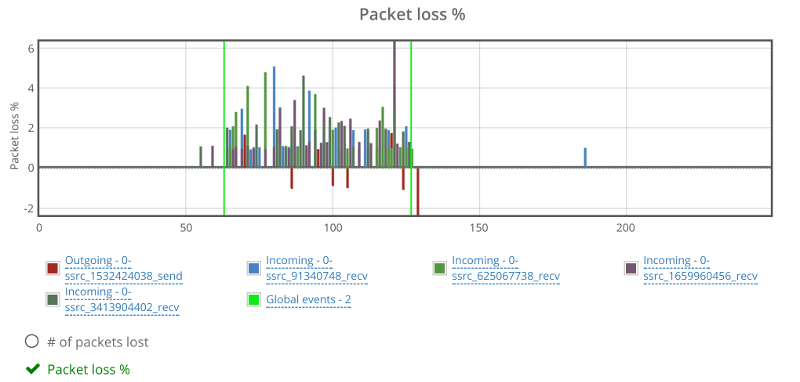
The graph seems fine. Percentages are low because of the way packet losses are reported back from the media server. Probably some FEC / retransmissions are involved as well (this would be the case with many of the media servers out there).
Looking at the video bitrate, we see an interesting picture:
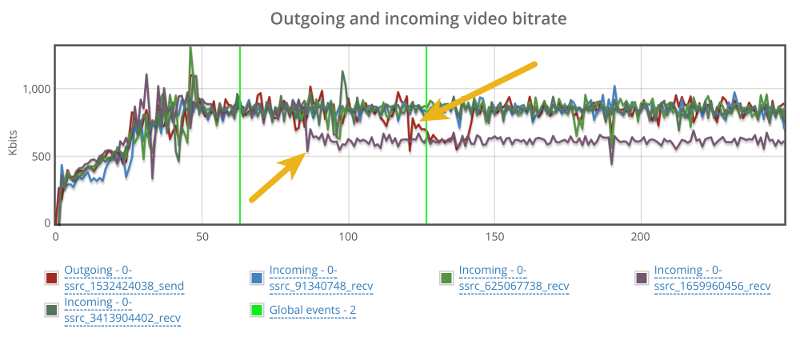
There’s a hiccup in the outgoing bitrate (the red line), but that for some reason takes place close to the end of the 60 seconds packet loss window.
There’s also a reduction in incoming bitrate for one of the video stream. It starts around 20 seconds into the packet loss zone, but it doesn’t recover even when we remove the packet losses.
Video delay is also a bit problematic:
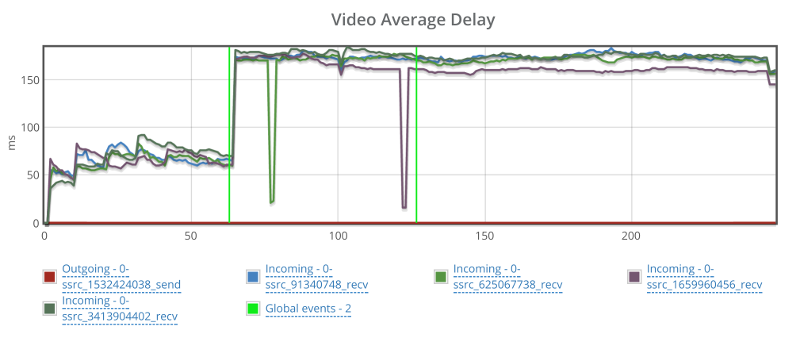
It starts off nicely, goes up when packet losses start and never recuperates.
SwitchRTC
Moving on from open source to commercial, there’s SwitchRTC.
It started by me asking for a 2mbps bitrate limit. Now, the way this was set up and without simulcast, it meant the browser is going to need to encode 2mbps and decode 4 streams of 2mbps each. This turned out to be a bit too much for the way we configure our machines (and frankly – probably too much for almost any use case you plan on deploying when it comes to assuming what your typical customer may have).
The end result of it was graphs that went all over the place – each stream and each browser tried hard to compete on resources that were limited, and it wasn’t really nice.
So we dialed back down to 1mbps bitrate limit.
As always, let’s first look at the packet loss graph:
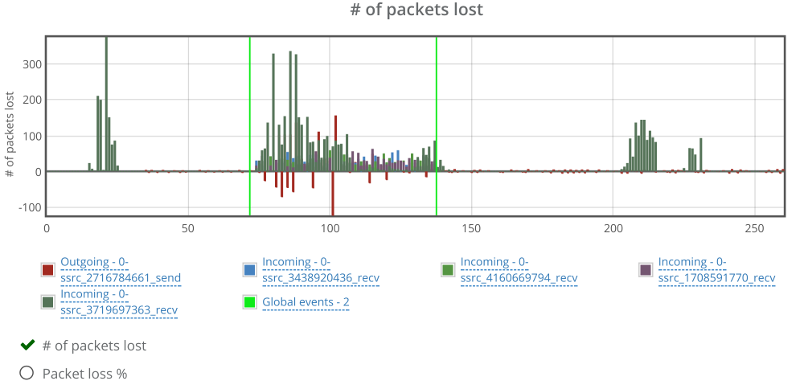
Two things here to note:
- One of the incoming video streams has packet losses outside the packet loss zone. Not unheard of, but a bit off the charges compared to others. I think that is due to the data centers used by SwitchRTC for this demo
- There’s negative packet losses on the outgoing video stream. This is due to the way SwitchRTC handles packet loss reporting (or more likely filtering packet loss reporting)
For bitrate, I took two screenshots. One for the incoming video streams and one for the outgoing video stream.
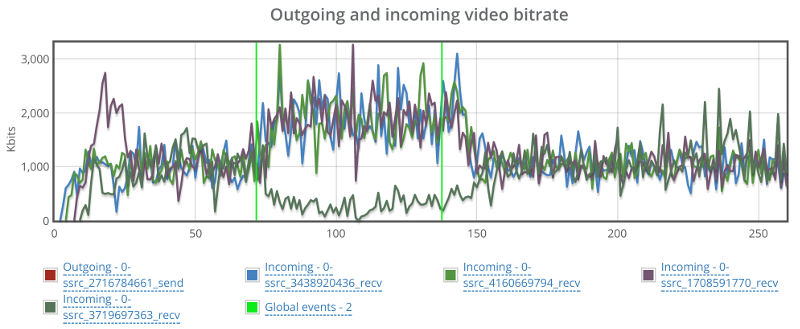
On the incoming stream we see an interesting phenomena.
When packet loss starts, bitrate picks up, most likely to overcome the packet loss. It makes sense, since we didn’t limit bitrates, so that seems like the correct strategy. Would be interesting to see what will happen if we limit bitrate as well.
The second thing, is that we have one of the incoming stream dropping down to almost zero and then picking up again. This is the same stream that shows high packet losses. I wonder what causes that.
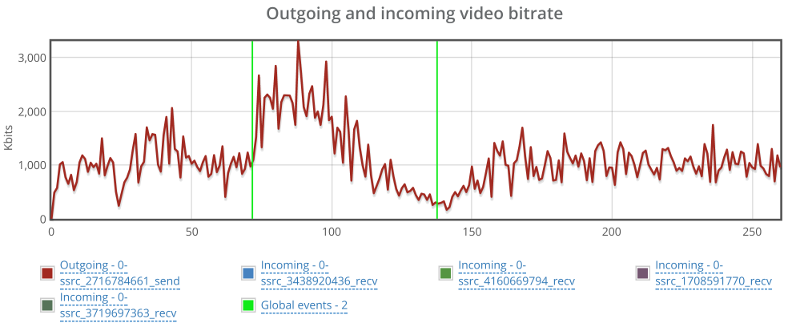
The graph above shows the outgoing video stream. This is almost textbook behavior for the outgoing video. Once it notices there’s issues, it starts increasing bitrate to compensate, and when that fails – it drops down slowly. It is similar, though not as smooth as what you see with AppRTC.
appear.in
appear.in have a beta SFU, which Philipp Hancke was kind enough to let me use.
Now, appear.in isn’t a media server or a component you can use in your own service – it is a full service, which makes this comparison a bit unfair – checking demos and comparing them to a commercial service.
But then I wanted to check this one out, as it isn’t based on any external framework – it was self developed in house at appear.in
The results are interesting.
Packet loss graph looks rather nice, if a tad low in the percentage:
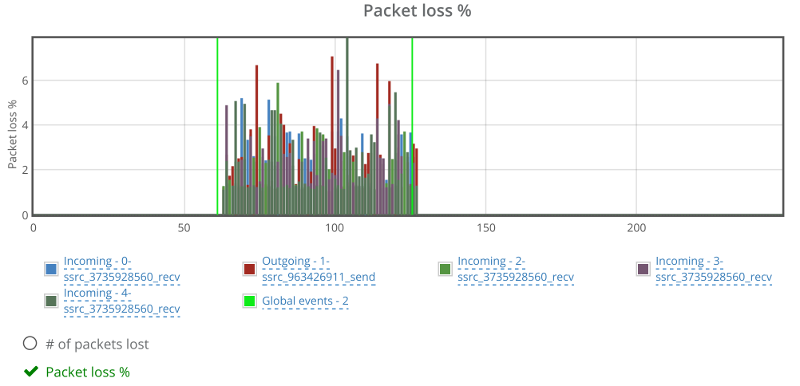
This shows how far appear.in goes in gauging and polishing the way they make use of network resources.
Video bitrate stays at the 600kbps vicinity – not showing any real effects from my additional packet loss:
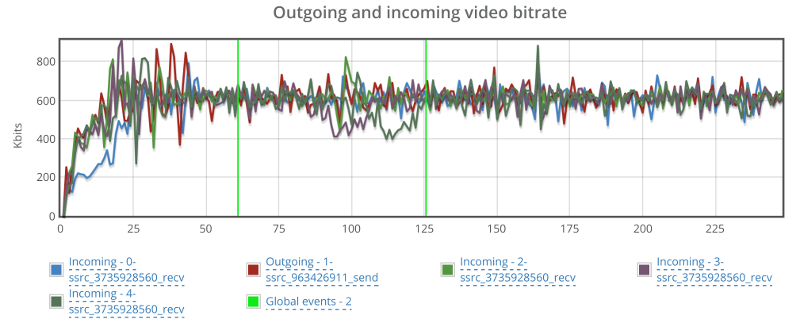
Best part though is that the video delay graph doesn’t look erratic:
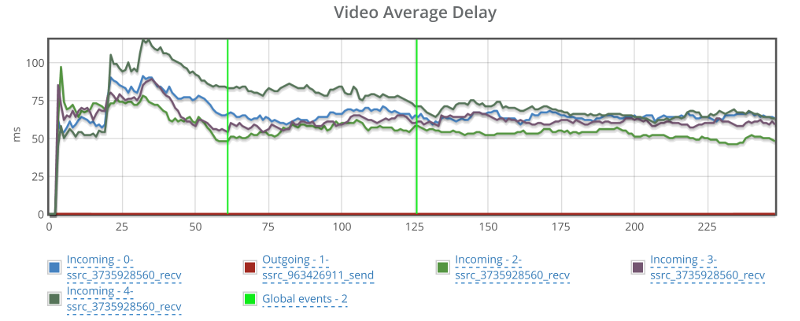
I am not sure how to compare these results to the rest. I will need more time to check this out – time that I just didn’t have available for this experiment of mine. I will leave it for some future tinkering.
Summing things up
Different media servers will act differently. Especially when putting them under different network conditions.
What I wanted to show here, is how you can use testRTC to goof around with whatever setting you want. Here are a few other ideas:
- Drop the network down to 0 bitrate. Wait a bit. Put it back up. Did media return? How quickly did it come up again?
- Limit bitrates to different levels. Check if your media server adapts things like resolutions and other interesting parameters to fit the needs
- Go down to 50 or 100 kbps. Does video persist or is the media server shutting it down in favor of audio?
- Limit bitrate and add a bit of packet loss at the same time (this would be closest to real life). See what happens then – how will the media server behave?
- Do the above while adding some load on the server. Does it start fidgeting or is it handling this nicely?
A few things to remember here:
This isn’t an apples to apples comparison
I haven’t taken each and every media server and installed it on my own on the same server configuration. I just used the online demos each of these vendors had. At times, asking for assistance and a bit of configuration from the vendor.
What was different:
- The server(s) the media server was installed on
- The configuration of the server, especially what max bitrate it allows
What was similar:
- I tried disabling simulcast in all servers. Assume that’s a bad thing to do, but I wanted a level playing field on that front
- The browser used. It was the same for all tests. This includes their version, the machine they were installed on, the network they used, their geographical location – everything
- The scenario itself. I essentially executed the same scenario over and over again in front of different media servers
Where do we go from here?
Media servers are hard to develop. They are hard to tweak and optimize. And they are hard when it comes to making sizing decisions with them.
They are also pretty good. Most of the ones shown here are running in production services with live customers.
When you go tomorrow to pick the media server for your own project. Or when you want to plan how to size capacities per machine. Or if you want to check your media server in real life scenarios – we’ve got your back.
Check us out. I am sure we can be of help to you.