How can watchRTC improve your WebRTC service operations?
watchRTC is our most recent addition to the testRTC product portfolio. It is a passive monitoring service that collects events information and metrics from WebRTC clients and analyzes, aggregates and visualizes it for you. It is a powerful WebRTC monitoring and troubleshooting platform, meant to help you improve and optimize your service delivery.
It’s interesting how you can start building something with an idea of how your users will utilize it, to then find out that what you’ve worked on has many other uses as well.
This is exactly where I am finding myself with watchRTC. Now, about a year after we announced its private beta, I thought it would be a good opportunity to look at the benefits our customers are deriving out of it. The best way for me to think is by writing things down, so here are my thoughts at the moment:
Table of contents
- What is watchRTC and how does it work?
- #1- Bird’s eye view of your WebRTC operations
- #2- Drilldown for debugging and troubleshooting WebRTC issues
- #3 – Monitoring WebRTC at scale
- #4 – Application data enrichment and insights
- #5 – Deriving business intelligence
- #6 – Rating, billing and reporting
- #7 – Optimization of media servers and client code
- #8 – A/B testing
- #9 – Manual testing
- watchRTC – run your WebRTC deployment at the speed of thought
What is watchRTC and how does it work?
watchRTC collects WebRTC related telemetry data from end users, making it available for analysis in real time and in aggregate.
For this to work, you need to integrate the watchRTC SDK into your application. This is straightforward integration work that takes an hour or less. Then the SDK can collect relevant WebRTC data in the background, while using as little CPU and network resources as possible.
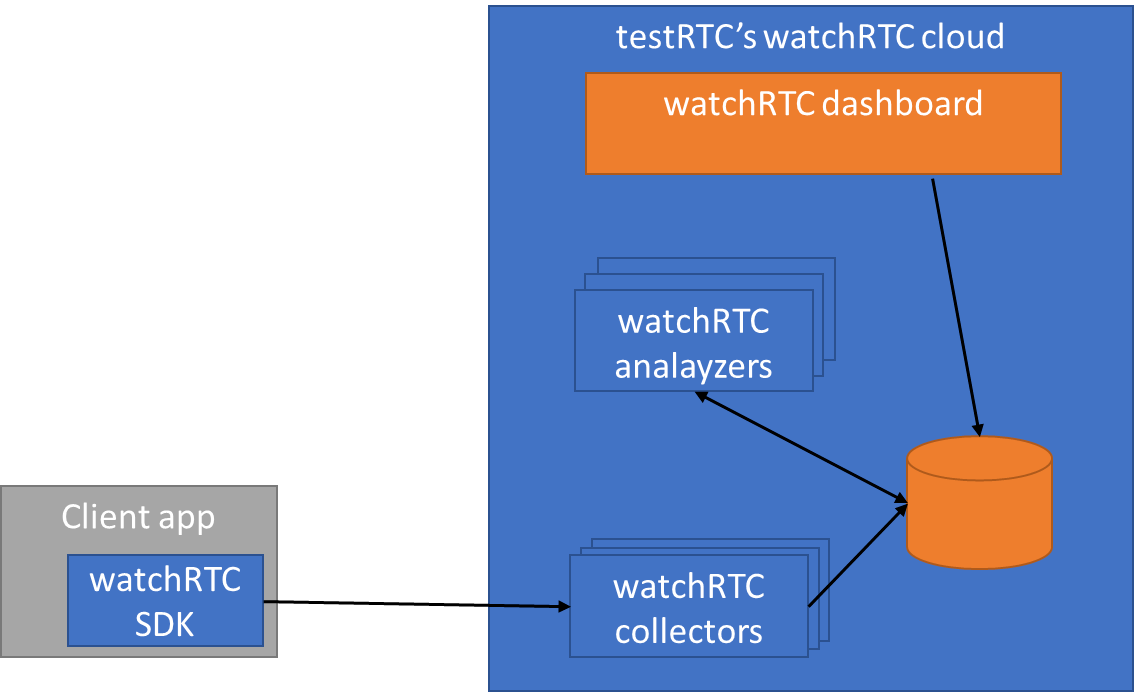
On the server side, we have a cloud service that is ready to collect this telemetry data. This data is made available in real-time for our watchRTC Live feature. Once the session completes and the room closes, the collected data can get further analyzed and aggregated.
Here are 3 objectives we set out to solve, and 6 more we find ourselves helping with:
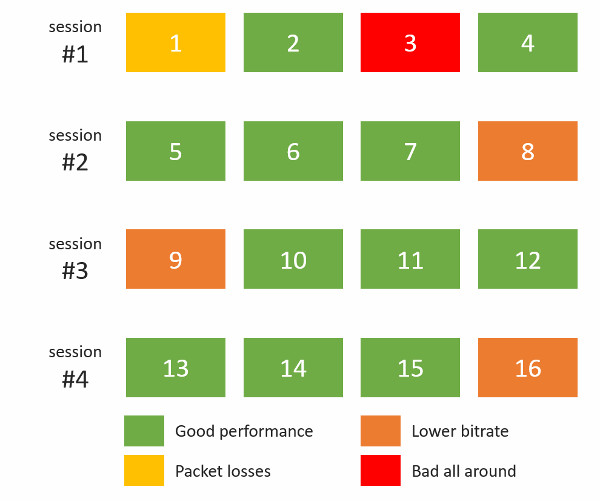
#1- Bird’s eye view of your WebRTC operations
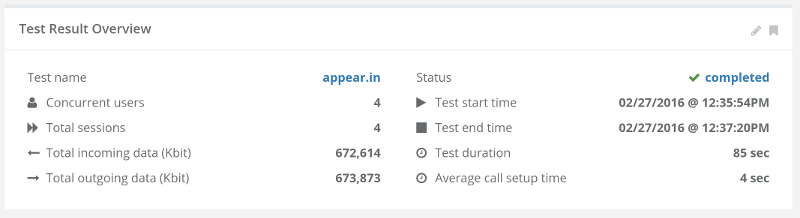
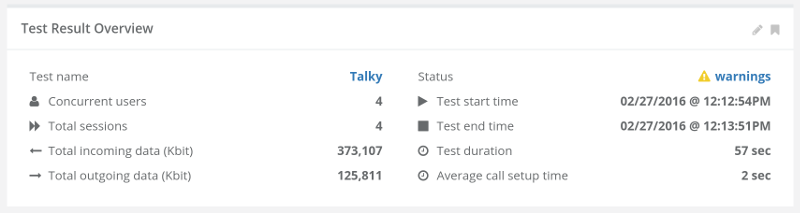
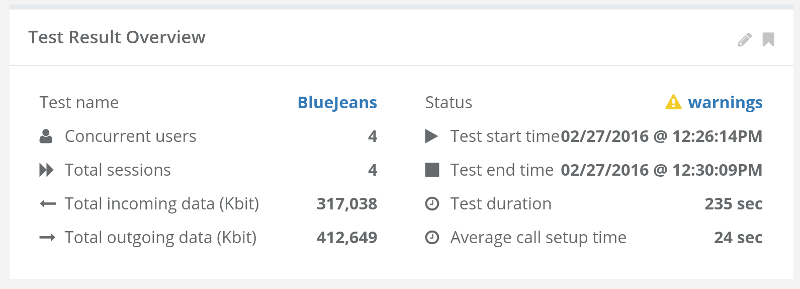
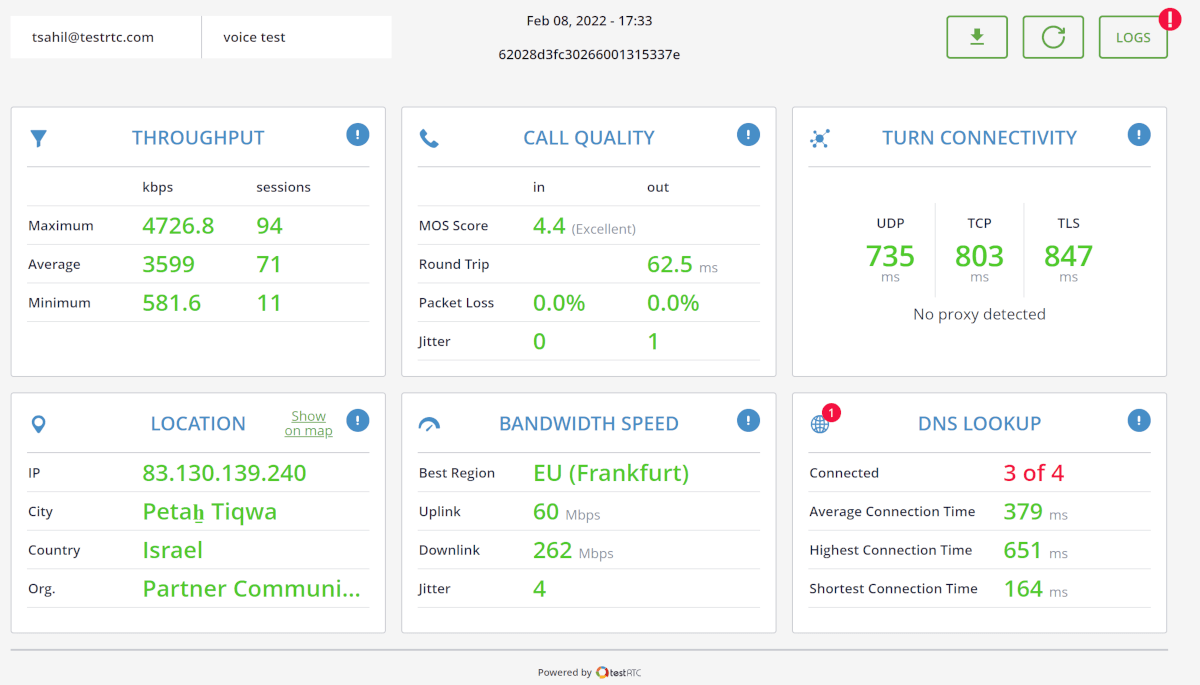
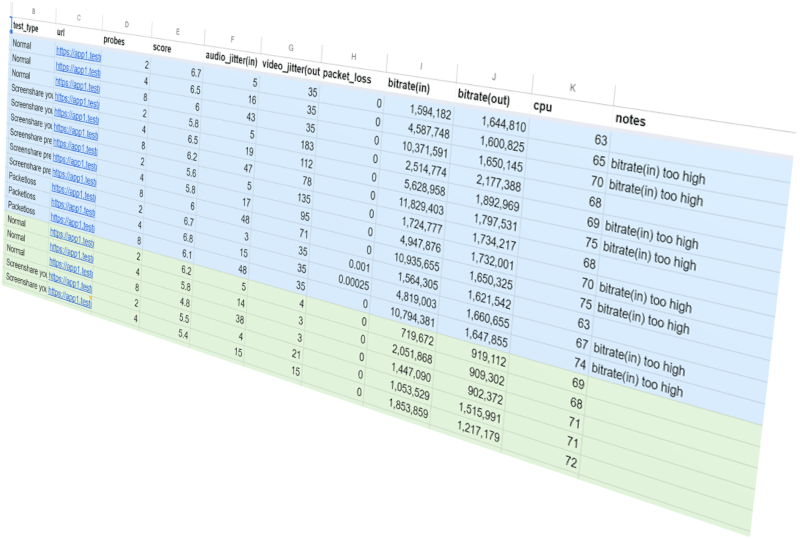
This is the basic thing you want from a WebRTC passive monitoring solution. It collects data from all WebRTC clients, aggregates and shows it on nice dashboards:
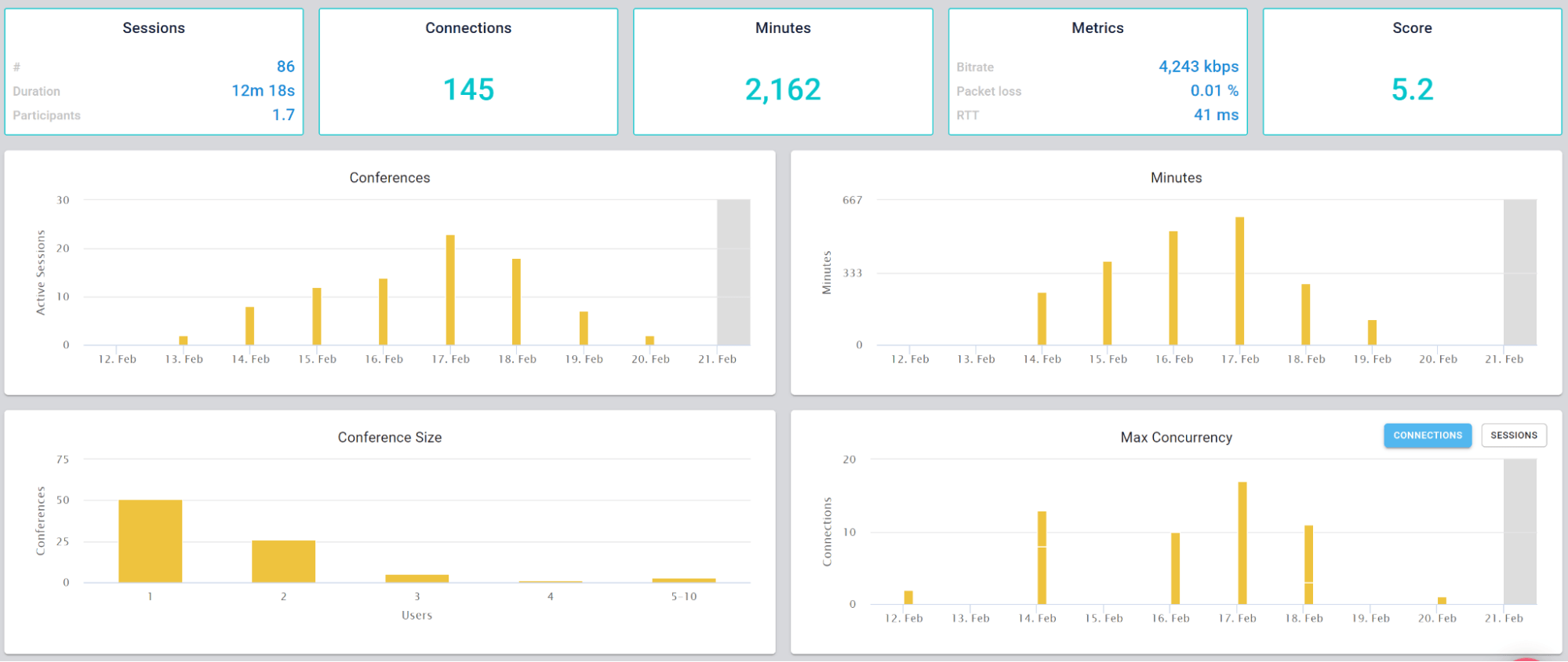
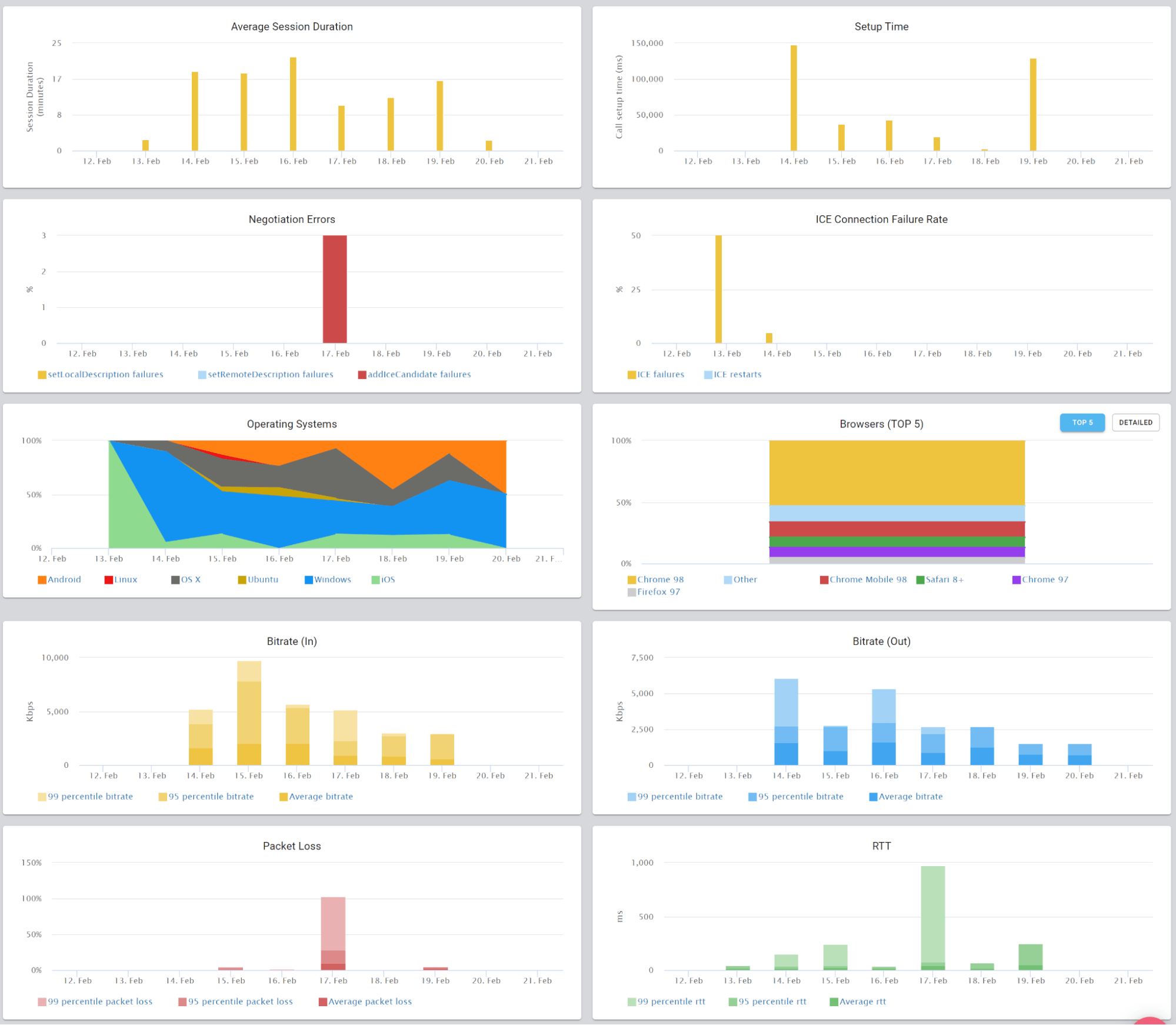
The result offers powerful overall insights into your users and how they are interacting with your service.
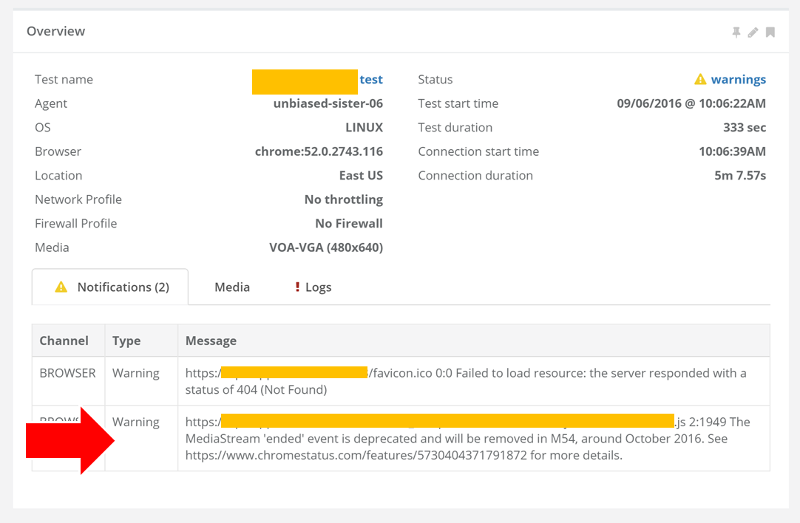
#2- Drilldown for debugging and troubleshooting WebRTC issues
watchRTC was built on the heels of other testRTC services. This means we came into this domain with some great tooling for debugging and troubleshooting automated tests.
With automated testing, the mindset is to collect anything and everything you can lay your hands on and make it as detailed as possible for your users to use it. Oh – and be sure to make it simple to review and quick to use.
We took that mindset to watchRTC with a minor difference – some limits on what we collect and how. While we’re running inside your application we don’t want to interrupt it from doing what it needs to do.
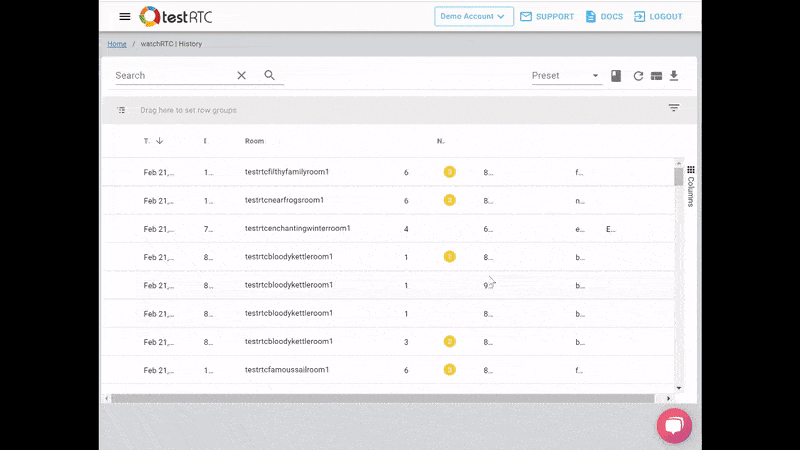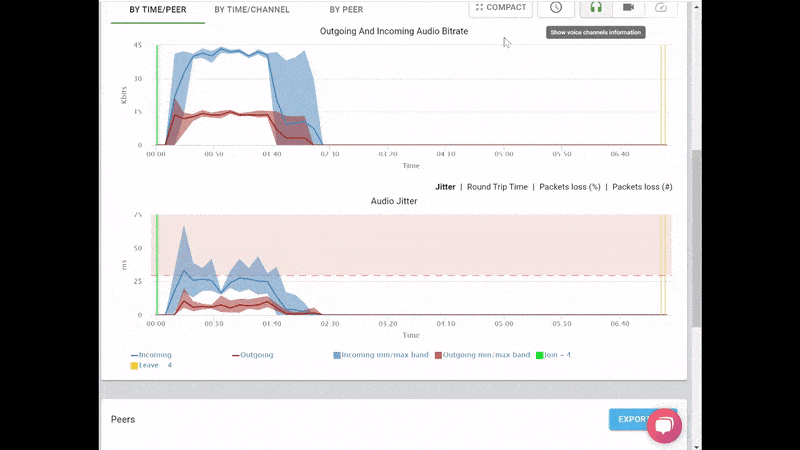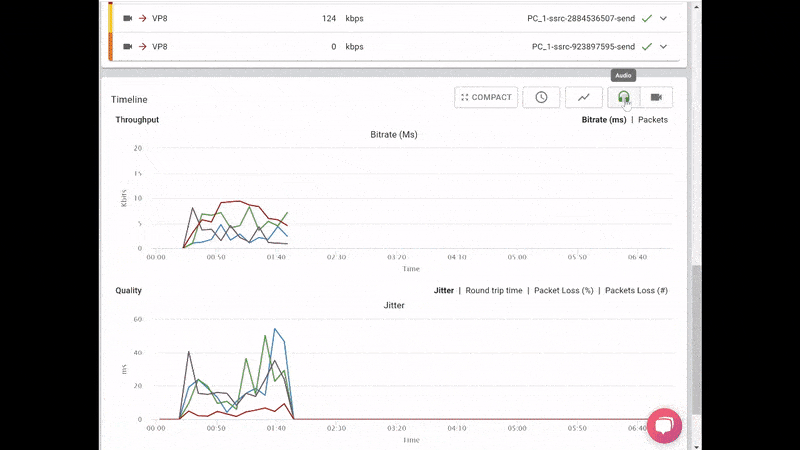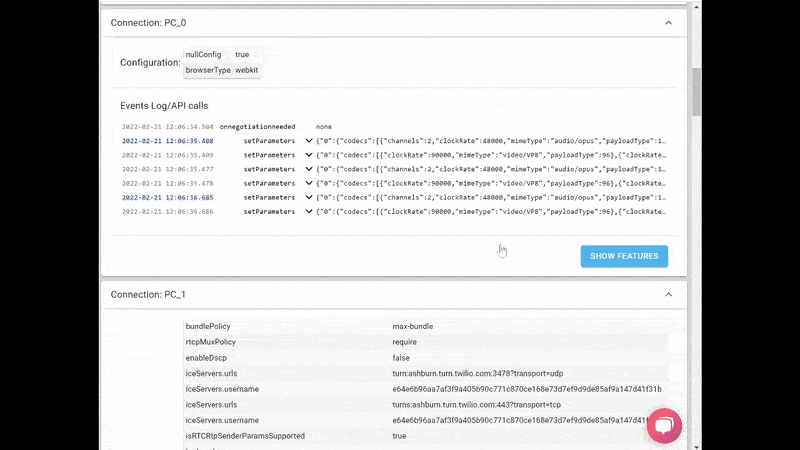
What we ended up with is the short video above.
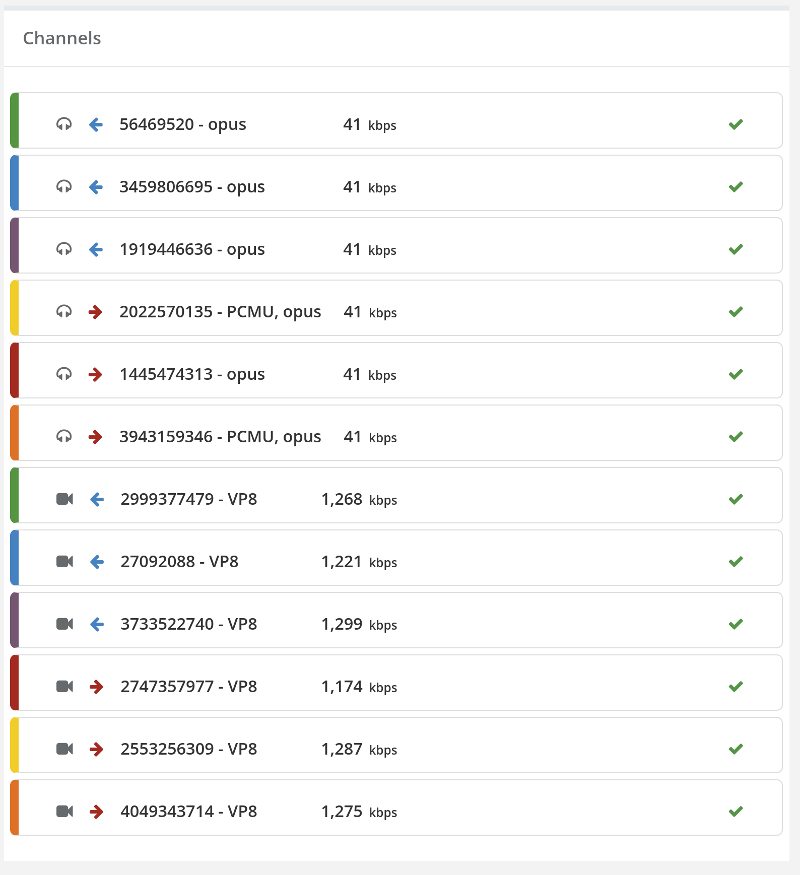
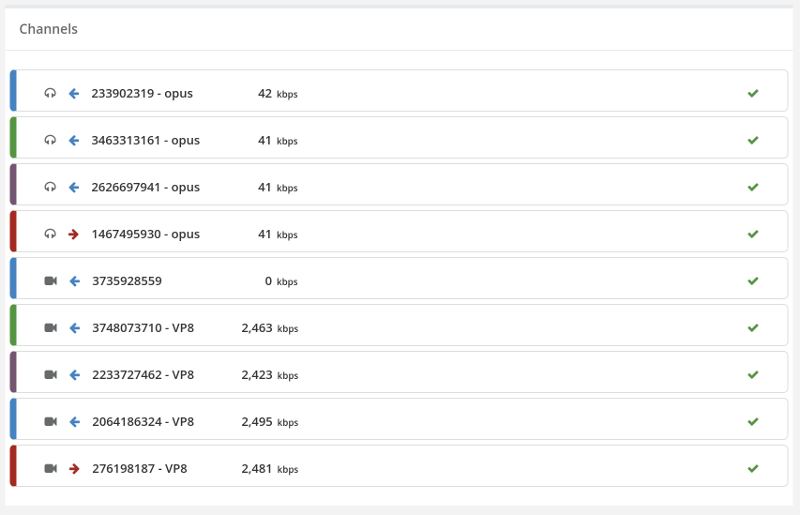
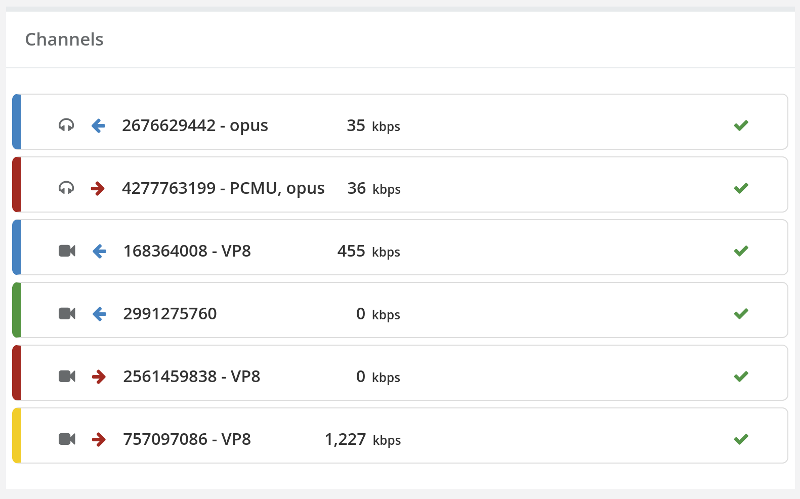
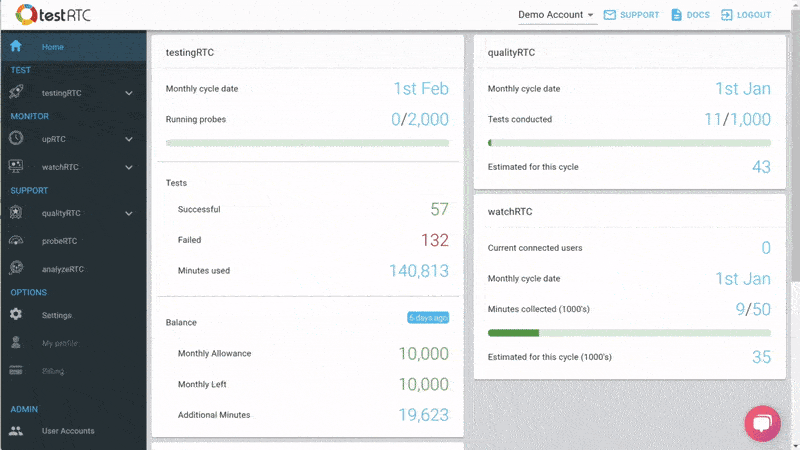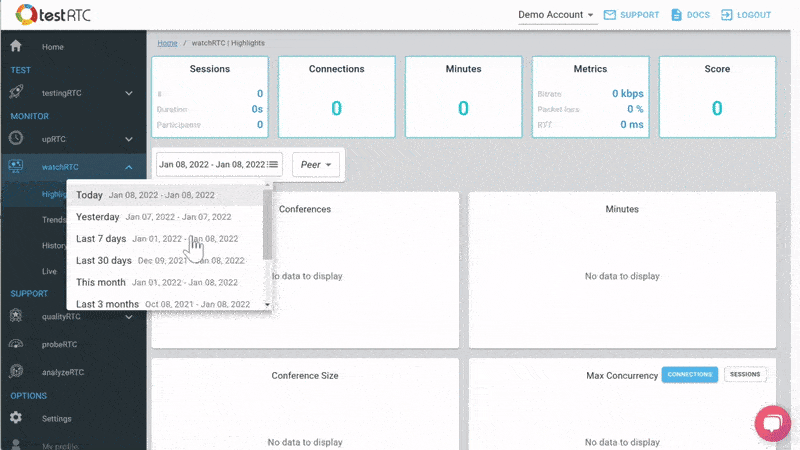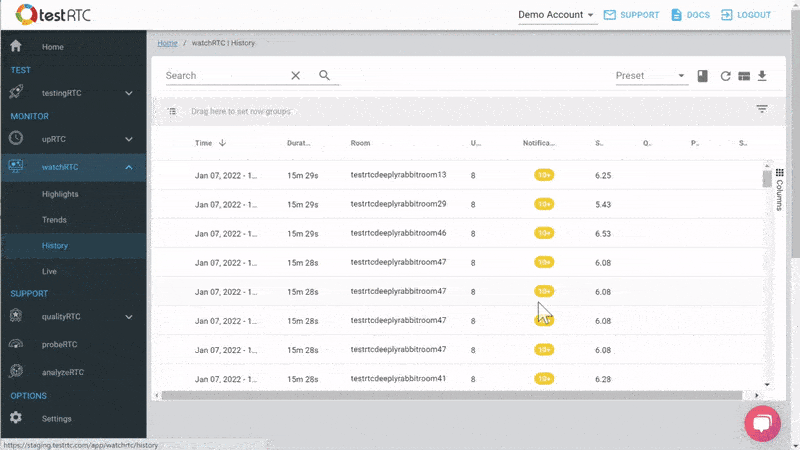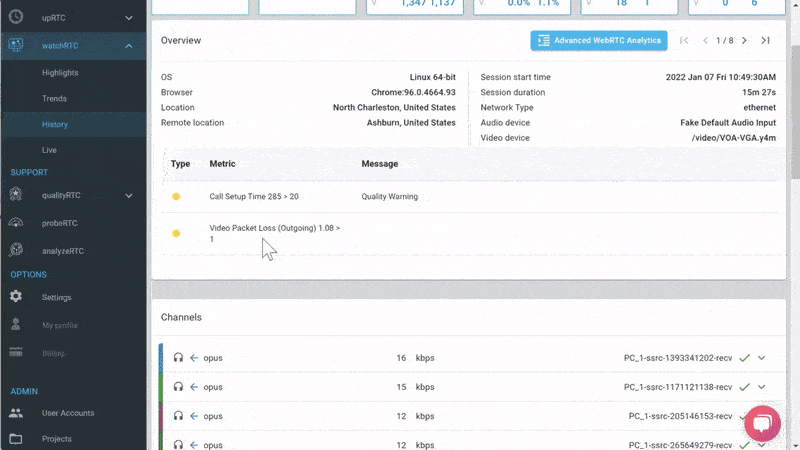
From a history view of all rooms (sessions) you can drill down to the room level and from there to the peer (user) level and finally from there to the detailed WebRTC analytics domain if and when needed.
In each layer we immediately highlight the important statistics and bubble up important notifications. The data is shown on interactive graphs which makes the work of debugging a lot simpler than any other means.
#3 – Monitoring WebRTC at scale
Then there’s the monitoring piece. Obvious considering this is a monitoring service.
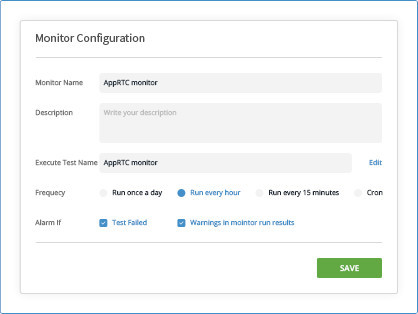
Here the intent is to bubble up discrepancies and abnormal behavior to the IT people.
We are doing that by letting you define the thresholds of various metric values and then bubbling up notifications when such thresholds are reached.
Now that we’re past the obvious, here are 5 more things our clients are doing with watchRTC that we didn’t think of when we started off with watchRTC:
#4 – Application data enrichment and insights
There’s WebRTC session data that watchRTC collects automatically, and then there’s the application related metadata that is needed to make more sense out of the WebRTC metrics that are collected.

This additional data comes in different shapes and sizes, and with each release we add more at our clients request:
- Share identifiers between the application and watchRTC, and quickly switch from one to the other across monitoring dashboards
- Add application specific events to the session’s timeline
- Map the names of incoming channels to other specific peers in a session
- Designate different peers with different custom keys
The extra data is useful for later troubleshooting when you need to understand who the users involved are and what actions have they taken in your application.
#5 – Deriving business intelligence
Once we started going, we got these requests to add more insights.
We already collect data and process it to show the aggregate information. So why not provide filters towards that aggregate information?

Starting with the basics, we let people investigate the information based on dates and then added custom keys aggregation.
Now? We’re full on with high level metrics – from browsers and operating systems, to score values, bitrates and packet loss. Slice and dice the metrics however you see fit to figure out trends within your own custom population filters.
On top of it all, we’re getting ready to bulk export the data to external BI systems of our clients – some want to be able to build their own queries, dashboards and enrichment.
#6 – Rating, billing and reporting
Interestingly, once people started using the dashboards they then wanted to be able to make use of it in front of their own customers.
Interestingly, not all vendors are collecting their own metrics for rating purposes. Being able to use our REST API to retrieve highlights for these, and base it on the filtering capabilities we have, enables exactly that. For example, you can put a custom key to denote your largest customers, and then track their usage of your service using our APIs.
Download information as PDFs with relevant graphs or call our API to get it in JSON format.
#7 – Optimization of media servers and client code
For developers, one huge attraction of watchRTC is their ability to optimize their infrastructure and code – including the media servers and the client code.
By using watchRTC, they can deploy fixes and optimizations and check “in the wild” how these affect performance for their users.
watchRTC collects every conceivable WebRTC metric possible, optimization work can be done on a wide range of areas and vectors as the results collected capture the needed metrics to decide the usefulness of the optimizations.
#8 – A/B testing
With watchRTC you can A/B test things. This goes for optimizations as well as many other angles.
You can now think about and treat your WebRTC infrastructure as a marketer would. By creating a custom key and marking different users with it, based on your own logic, you can A/B test the results to see what’s working and what isn’t.
It is a kind of an extension of optimizing media servers, just at a whole new level of sophistication.
#9 – Manual testing

If you remember, our origin is in testing, and testing is used by developers.
These same developers already use our stress and regression testing capabilities. But as any user relying on test automation will tell you – there are times when manual testing is still needed (and with WebRTC that happens quite a lot).
The challenge with manual testing and WebRTC is data collection. A tester decided to file a bug. Where does he get all of the information he needs? Did he remember to keep his chrome://webrtc-internals tab open and download the file on time? How long does it take him to file that bug and collect everything?
Well, when you integrate with watchRTC, all of that manual labor goes away. Now, the tester needs only to explain the steps that caused the bug and add a link to the relevant session in watchRTC. The developer will have all the logs already there.
With watchRTC, you can tighten your development cycles and save expensive time for your development team.
watchRTC – run your WebRTC deployment at the speed of thought

One thing we aren’t compromising with watchRTC is speed and responsiveness. We work with developers and IT people who don’t have the time to sit and wait for dashboards to load and update, therefore, we’ve made sure and are making it a point for our UI to be snappy and interactive to the extreme.
From aggregated bird’s eye dashboard, to filtering, searching and drilling down to the single peer level – you’ll find watchRTC a powerful and lightning fast tool. Something that can offer you answers the moment you think of the questions.
If you’re new to testRTC and would like to find out more we would love to speak with you. Please send us a brief message, and we will be in contact with you shortly.




")

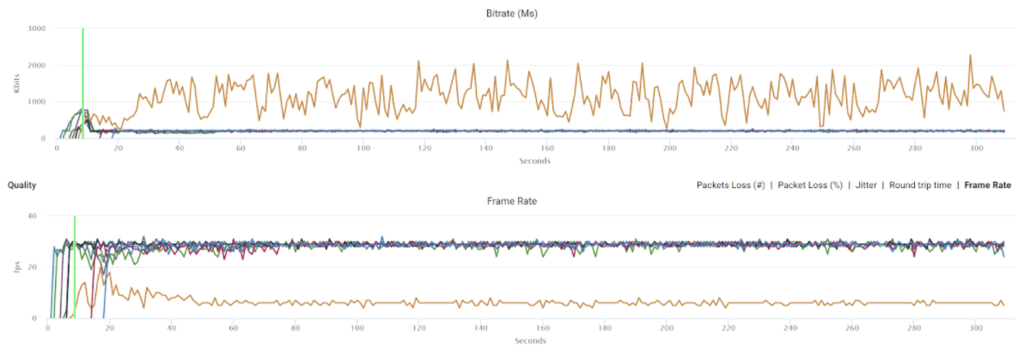










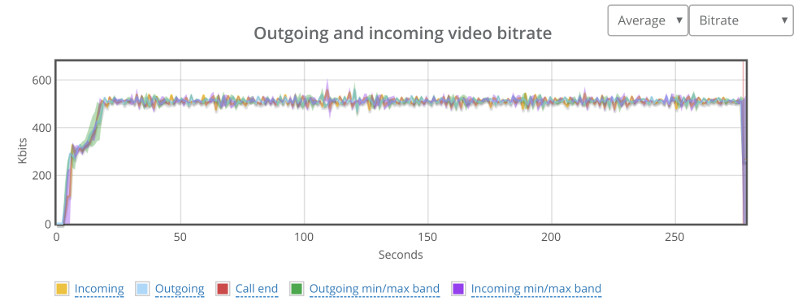
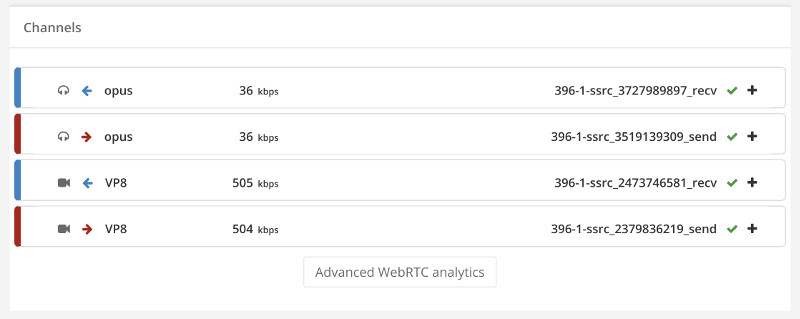
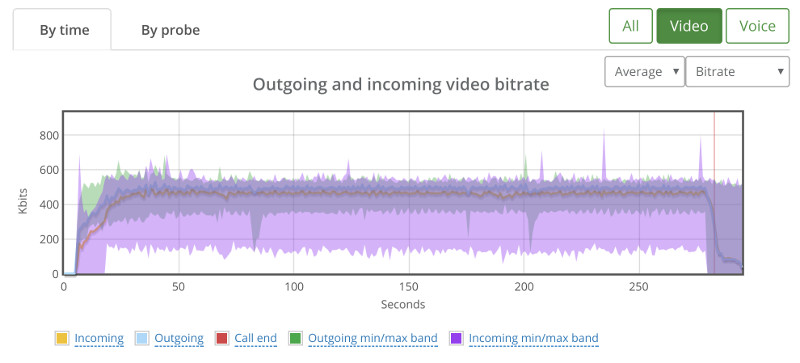
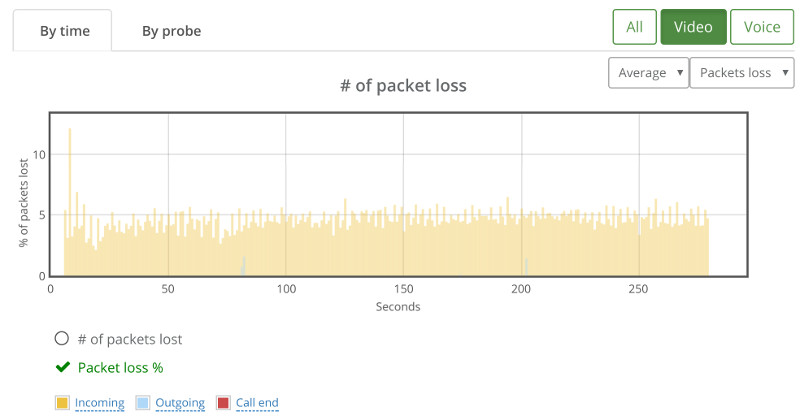
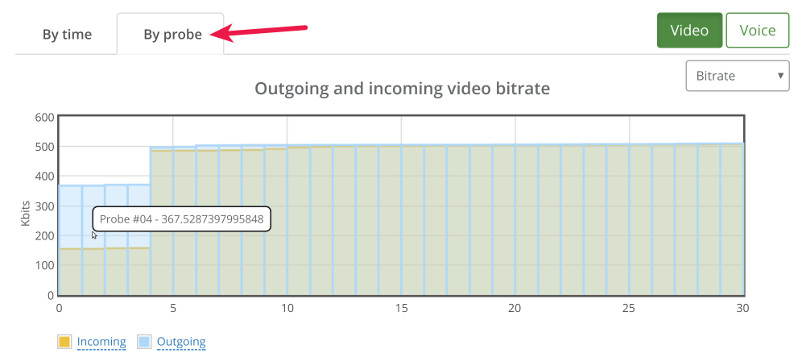
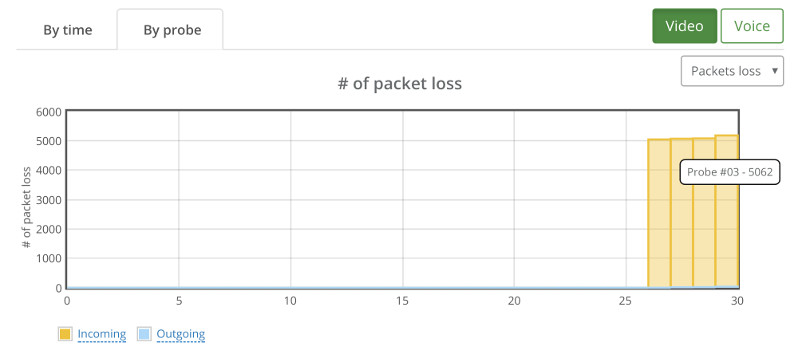
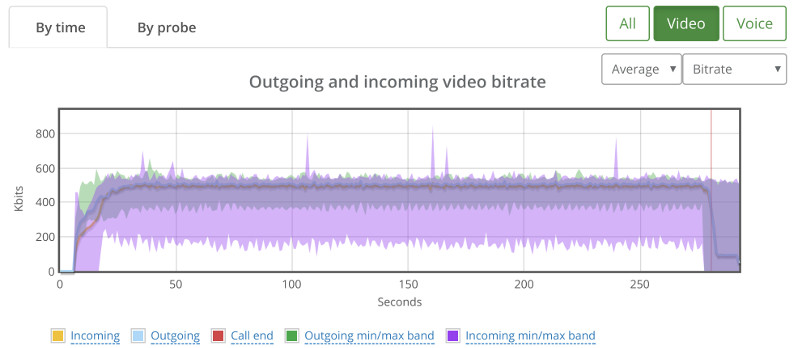
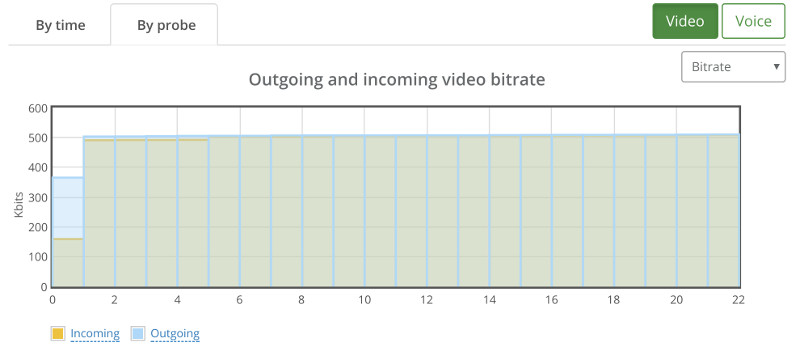
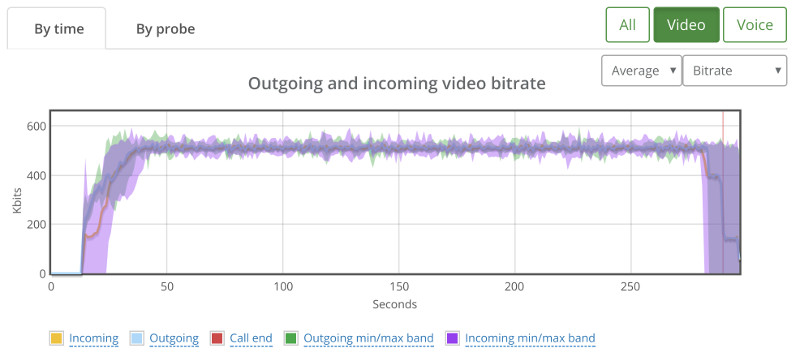
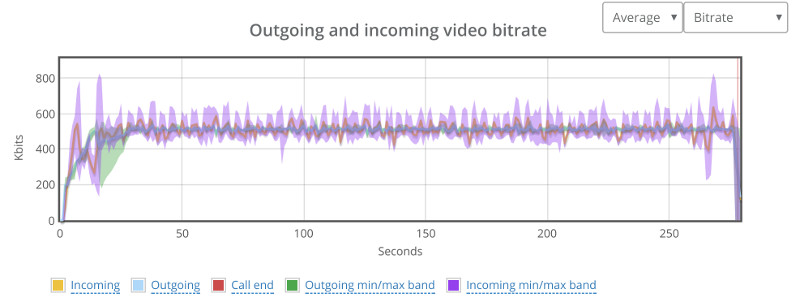
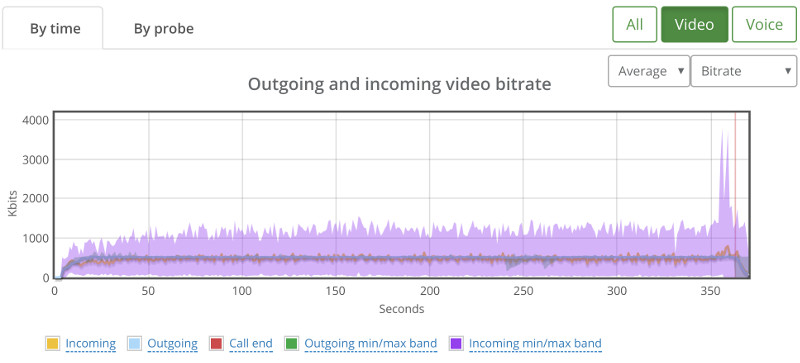
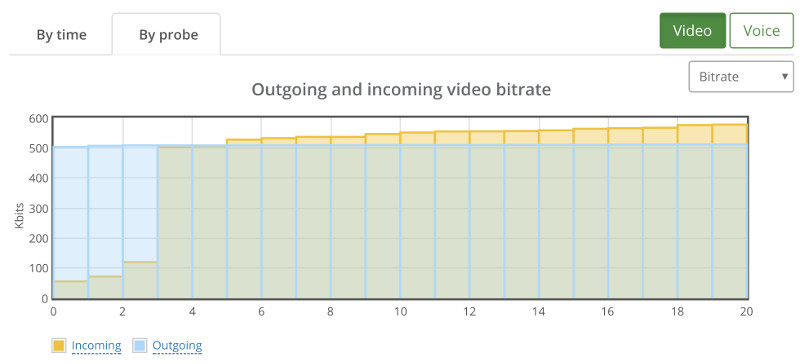
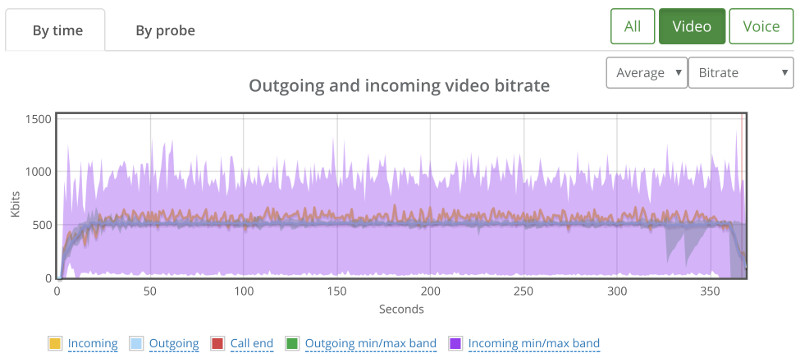
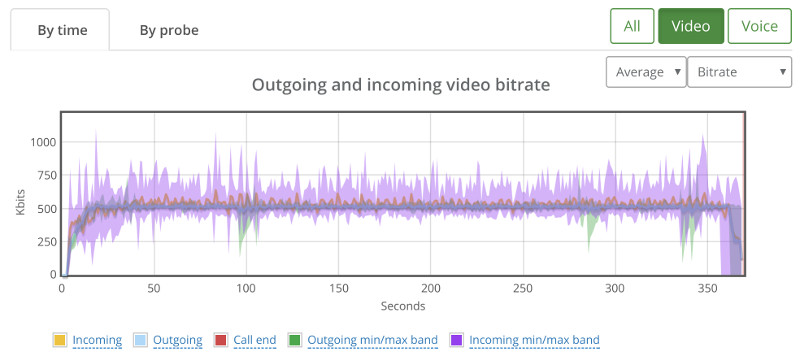
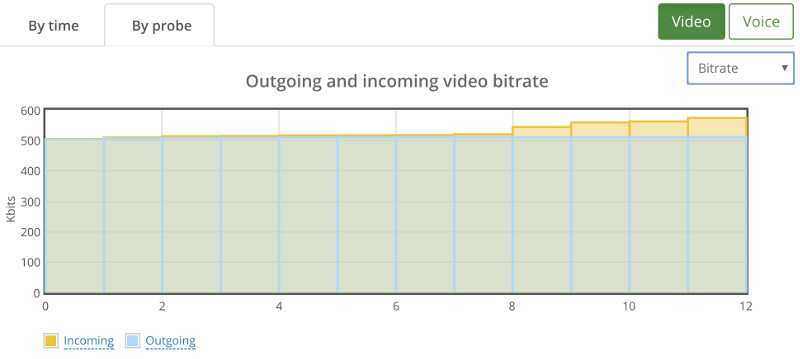

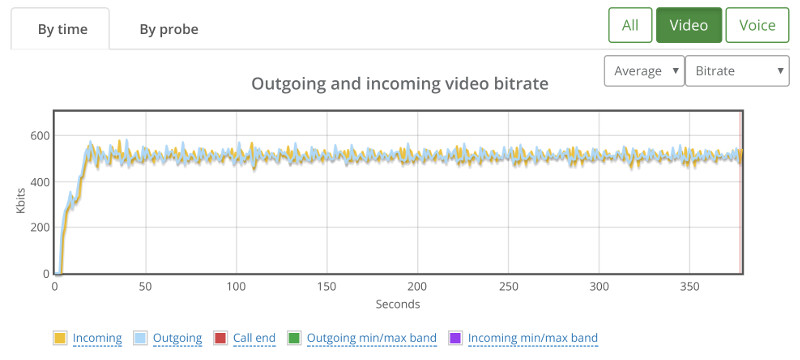

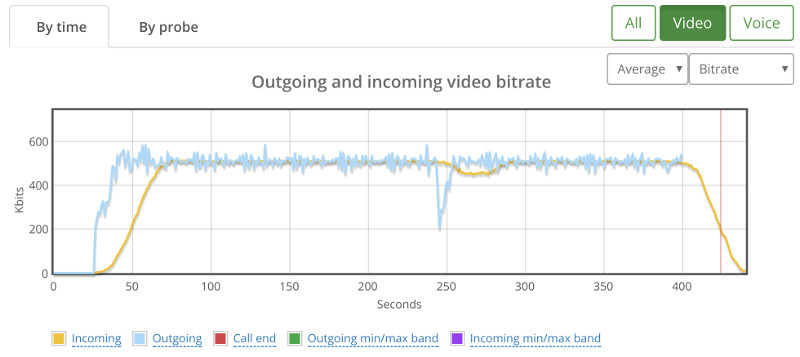




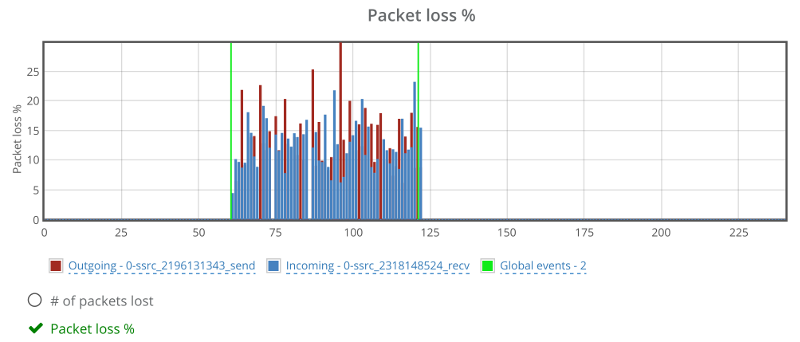
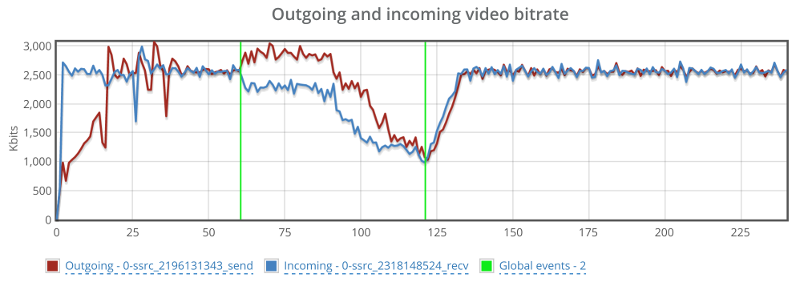
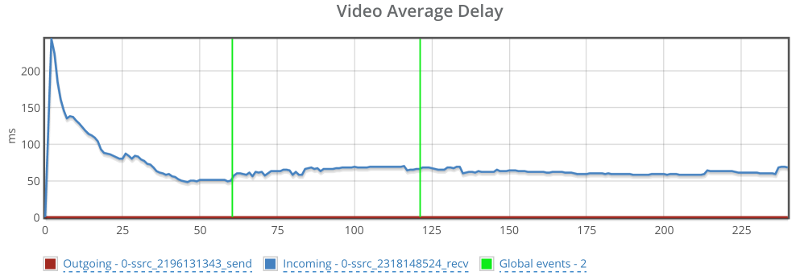
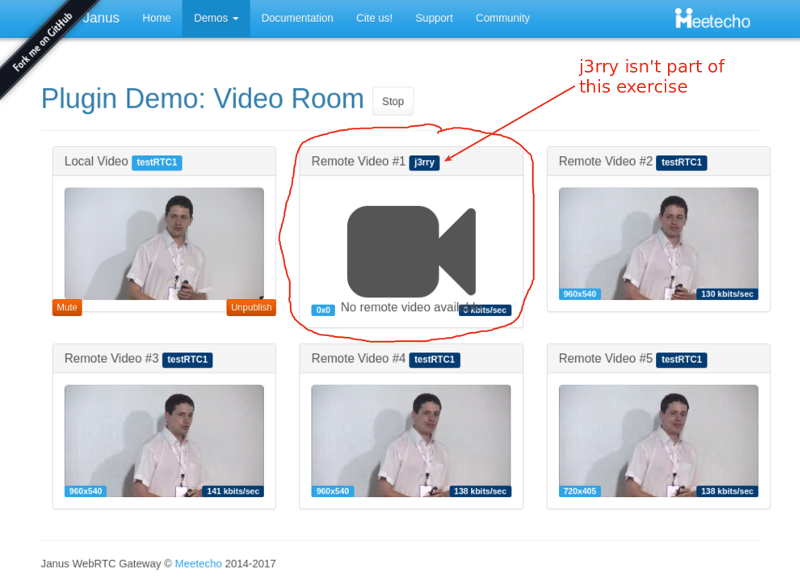
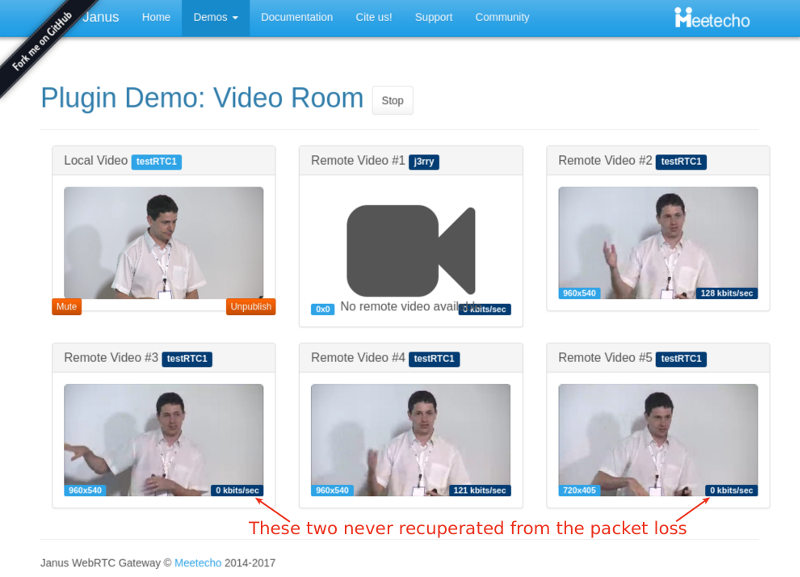
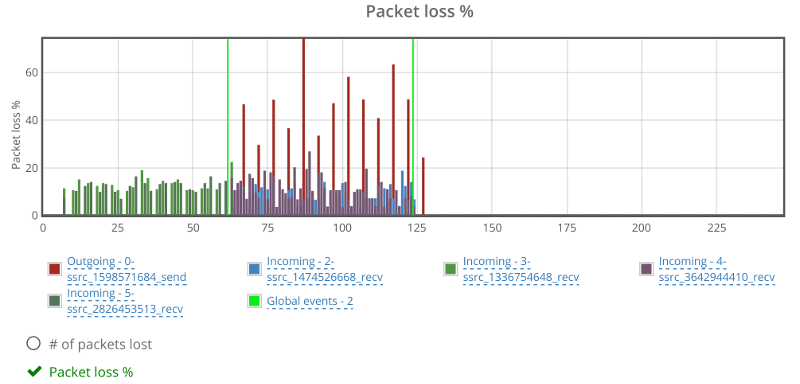
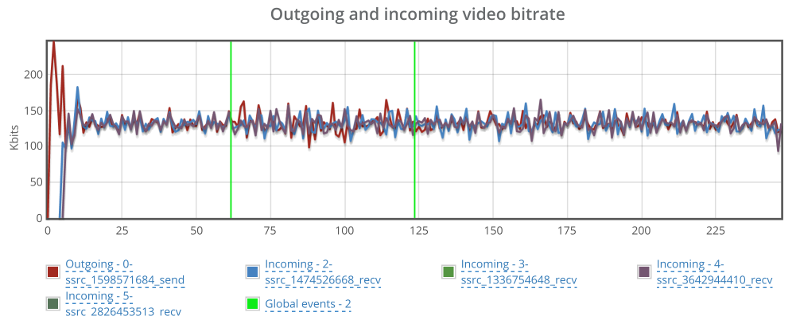
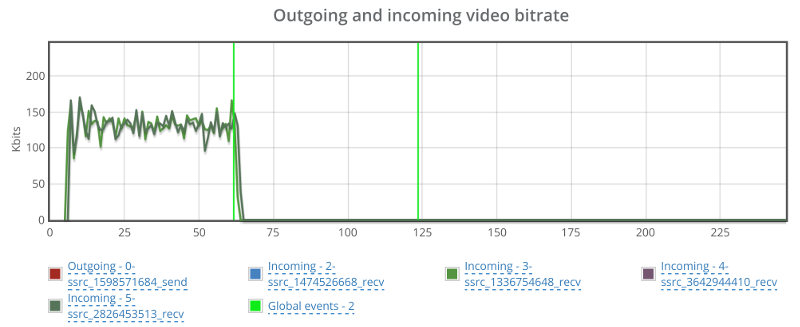
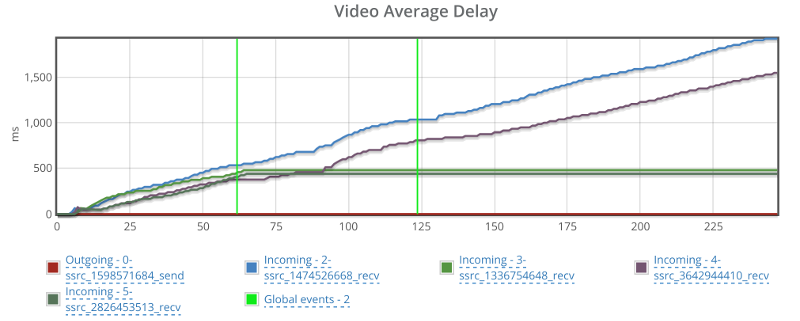
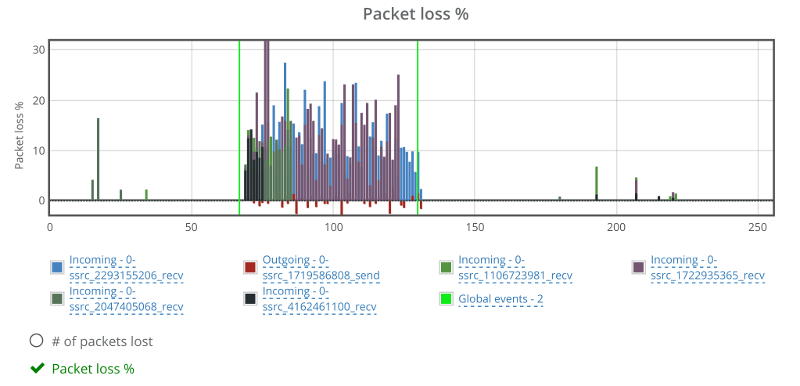
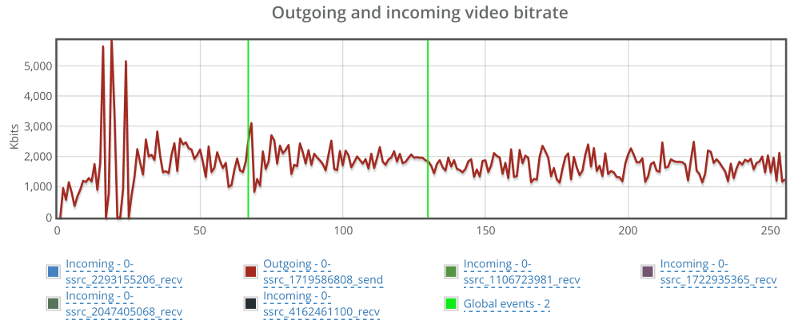
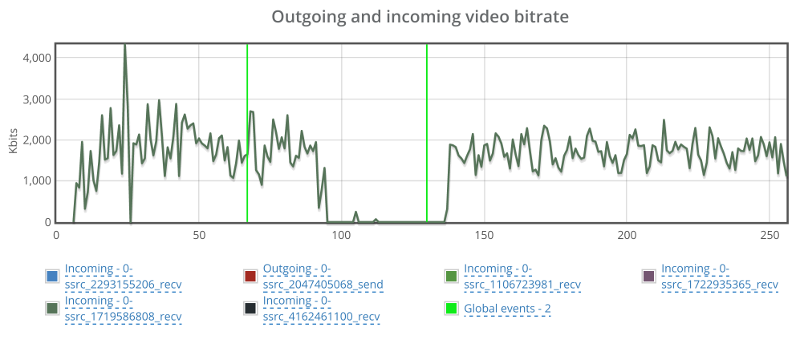
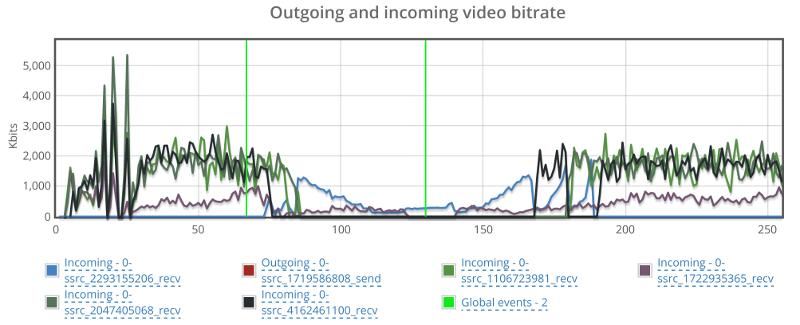
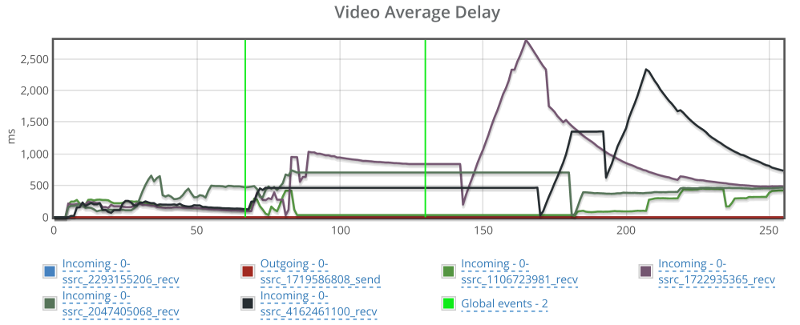
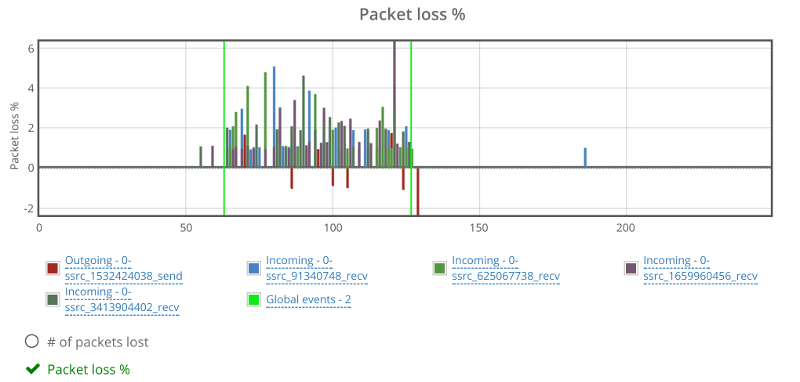
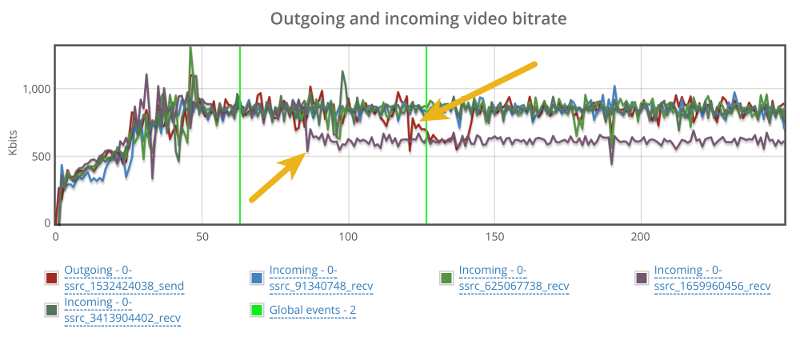
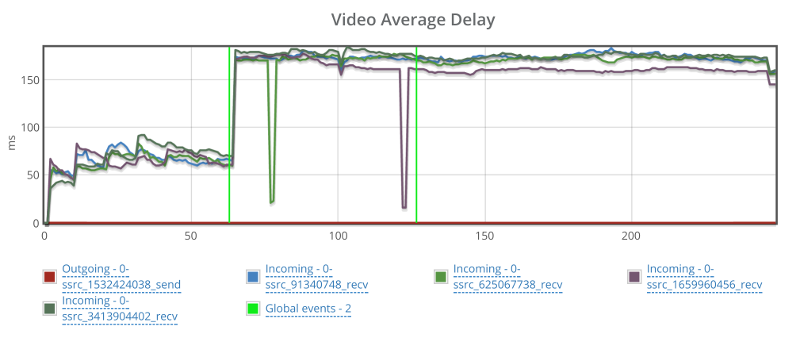
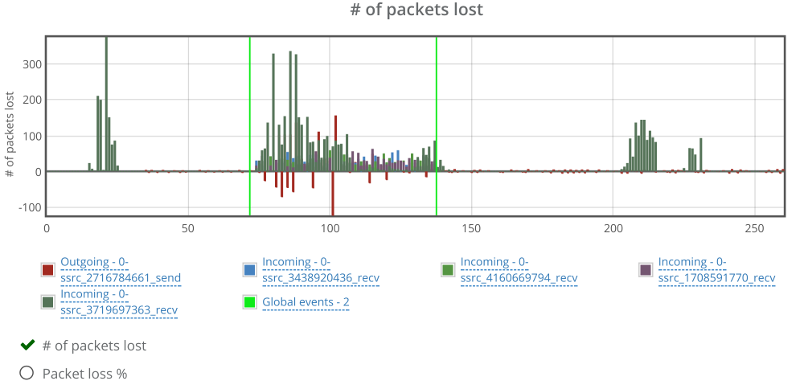
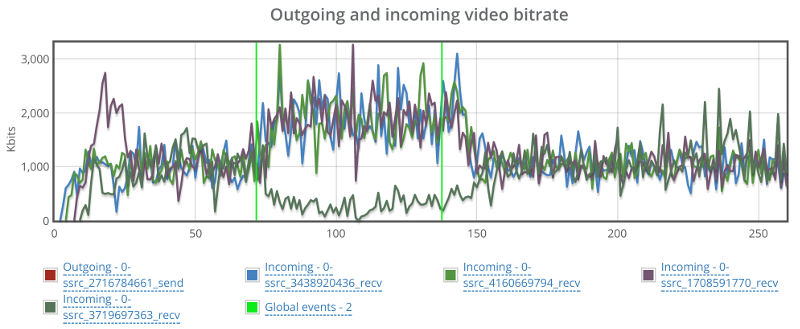
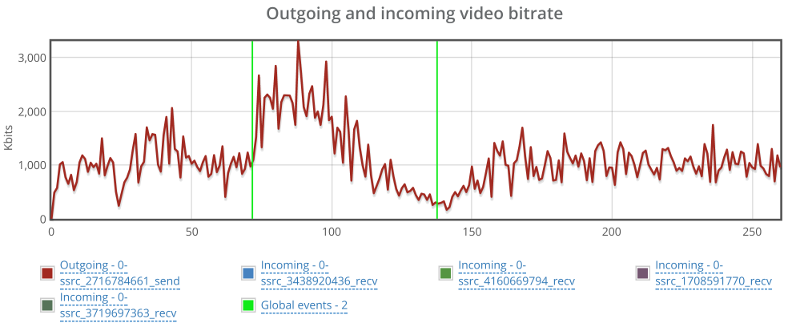
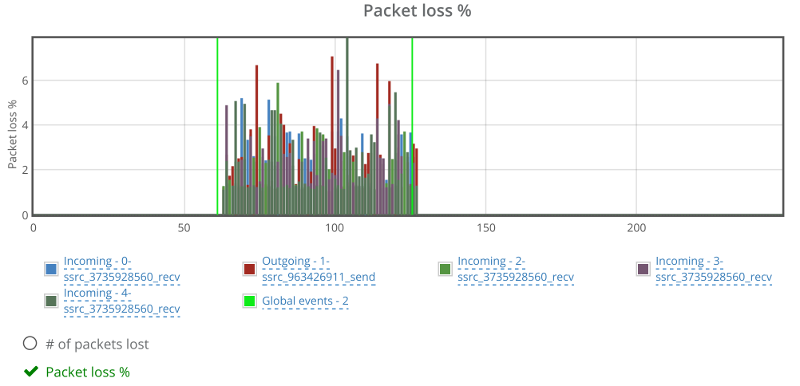
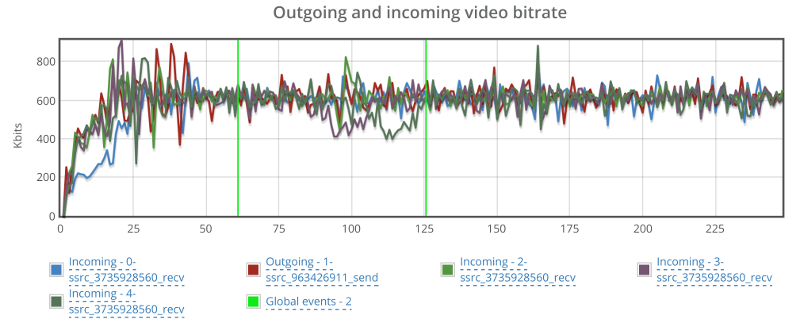
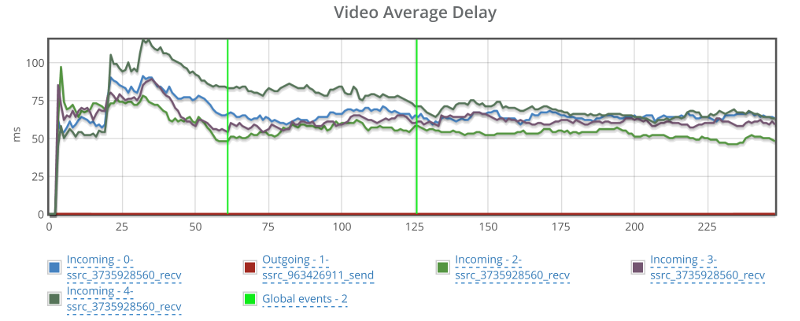

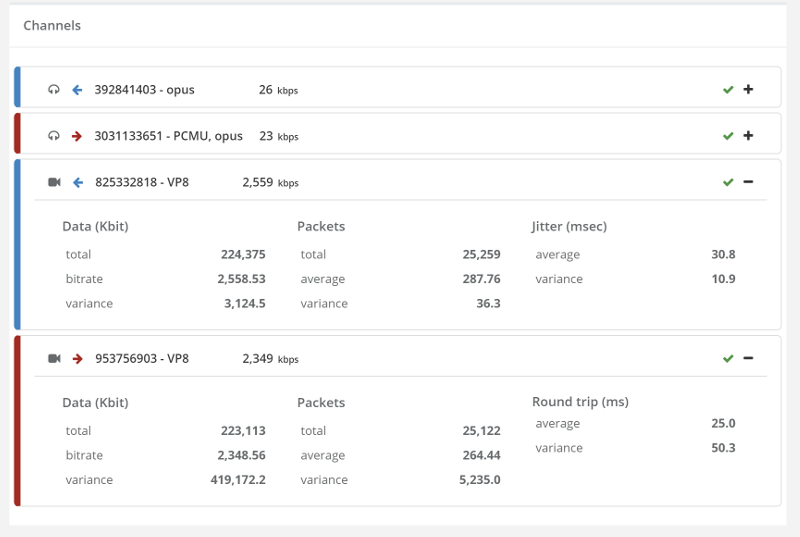
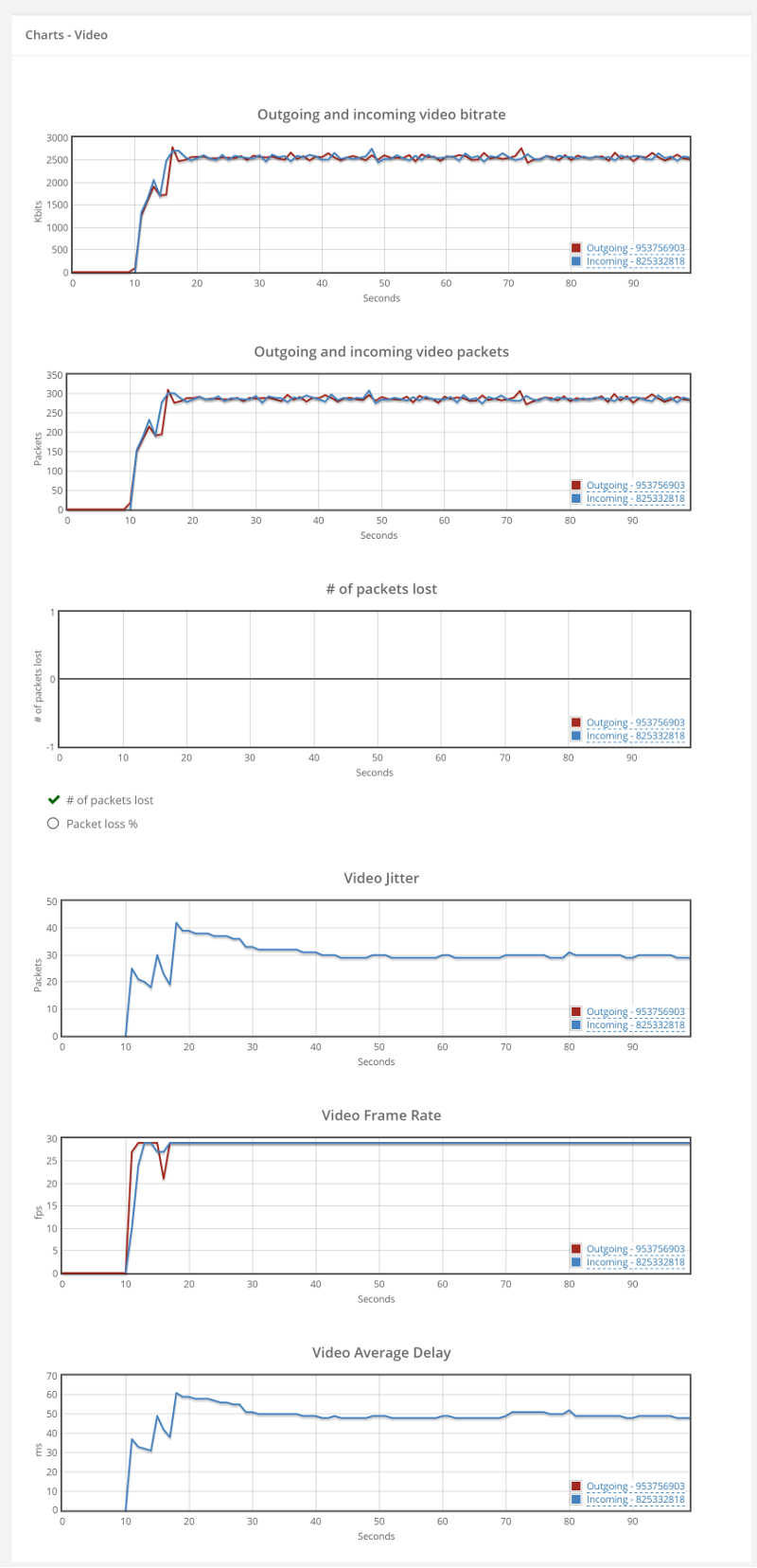
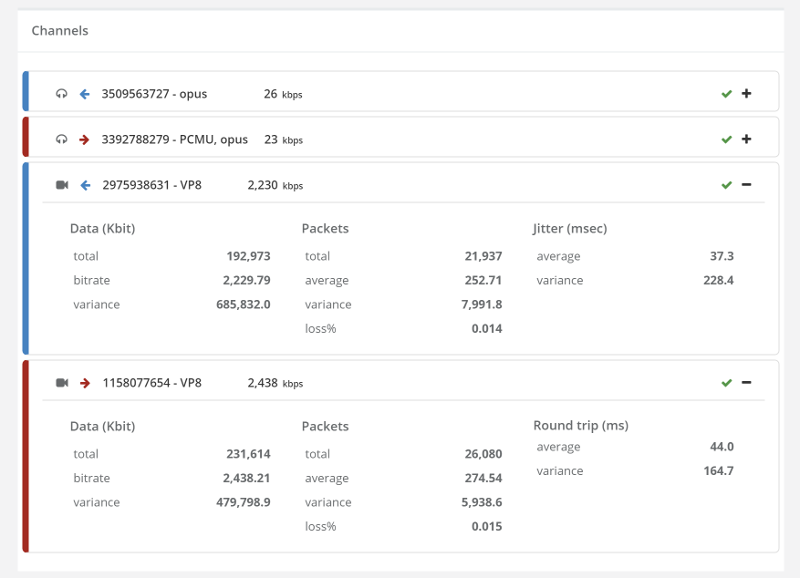
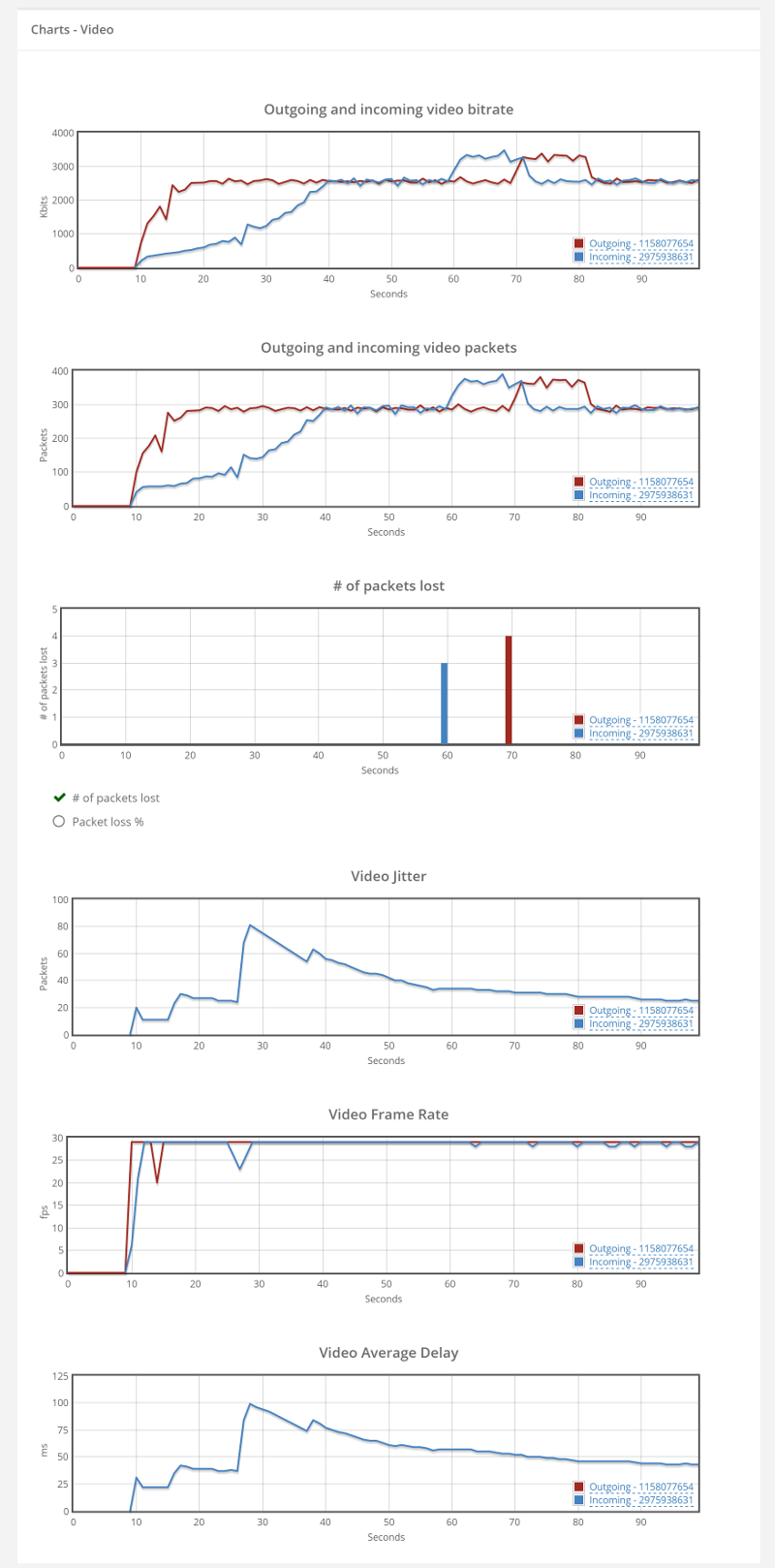
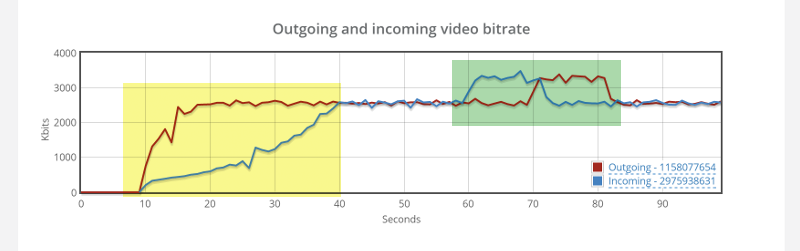
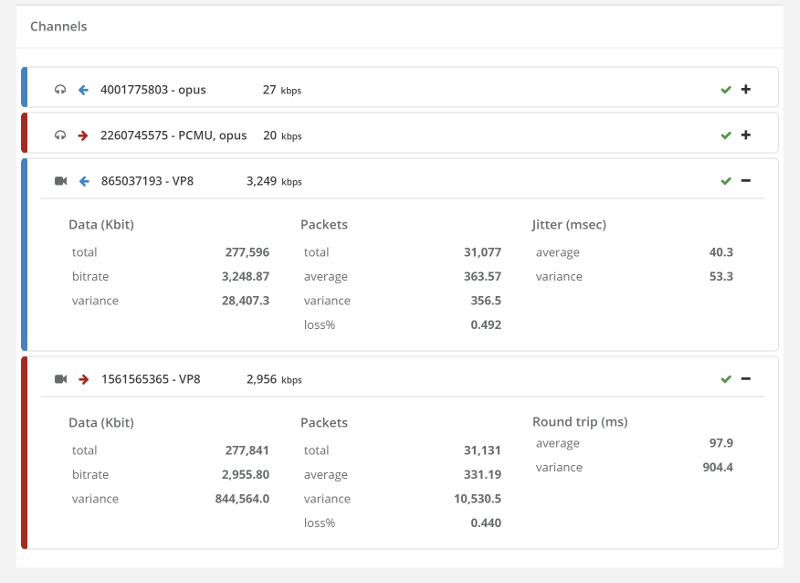

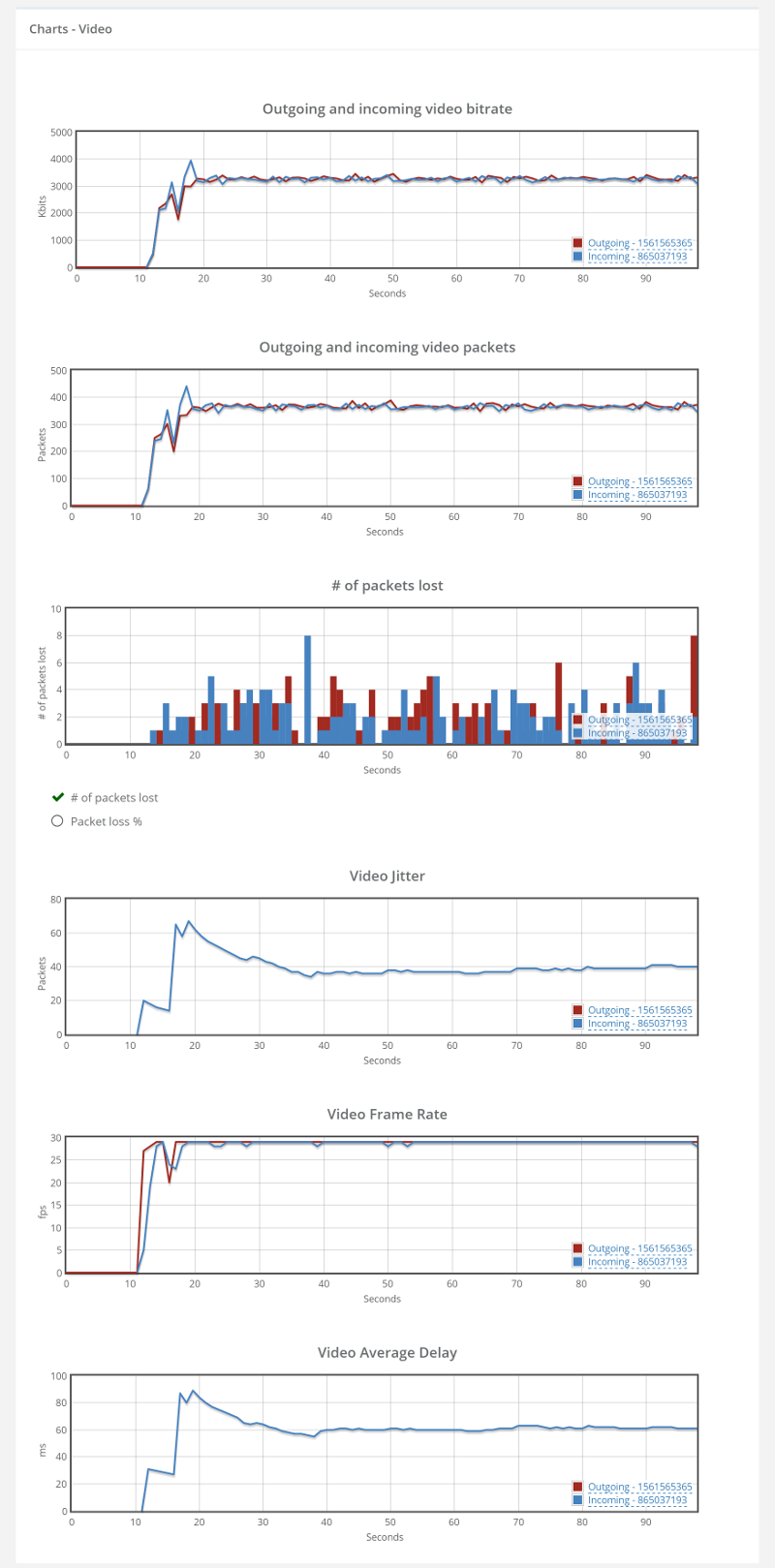
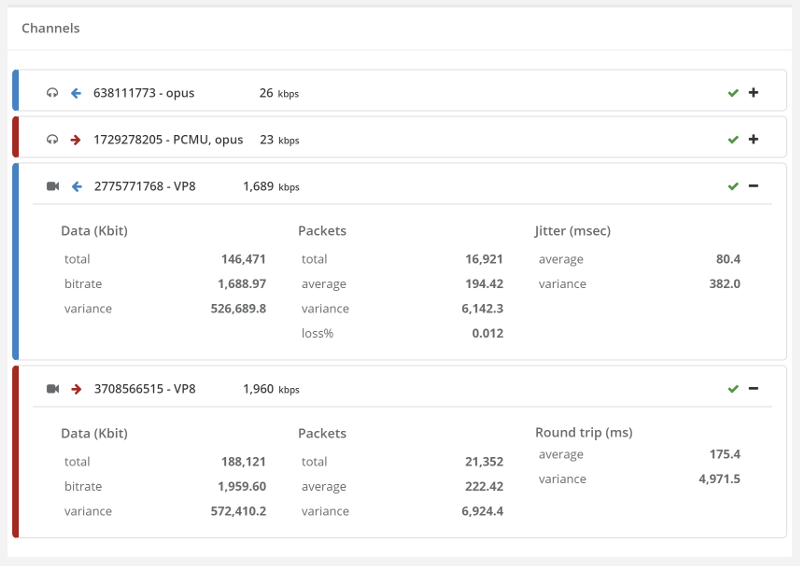
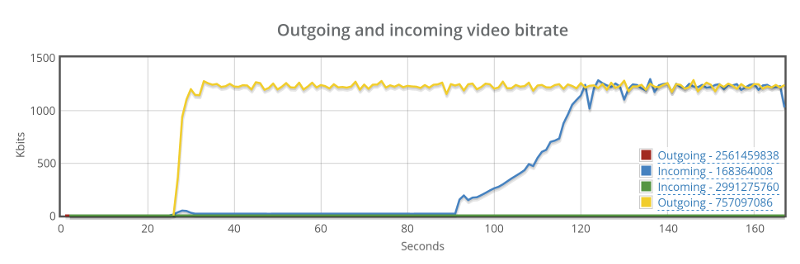
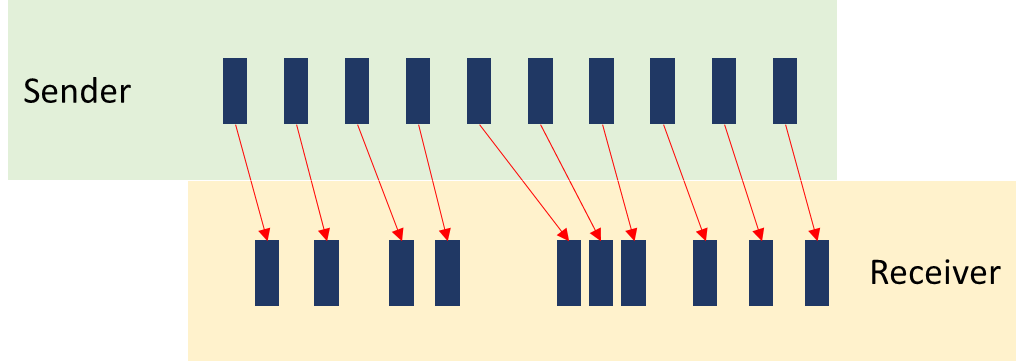
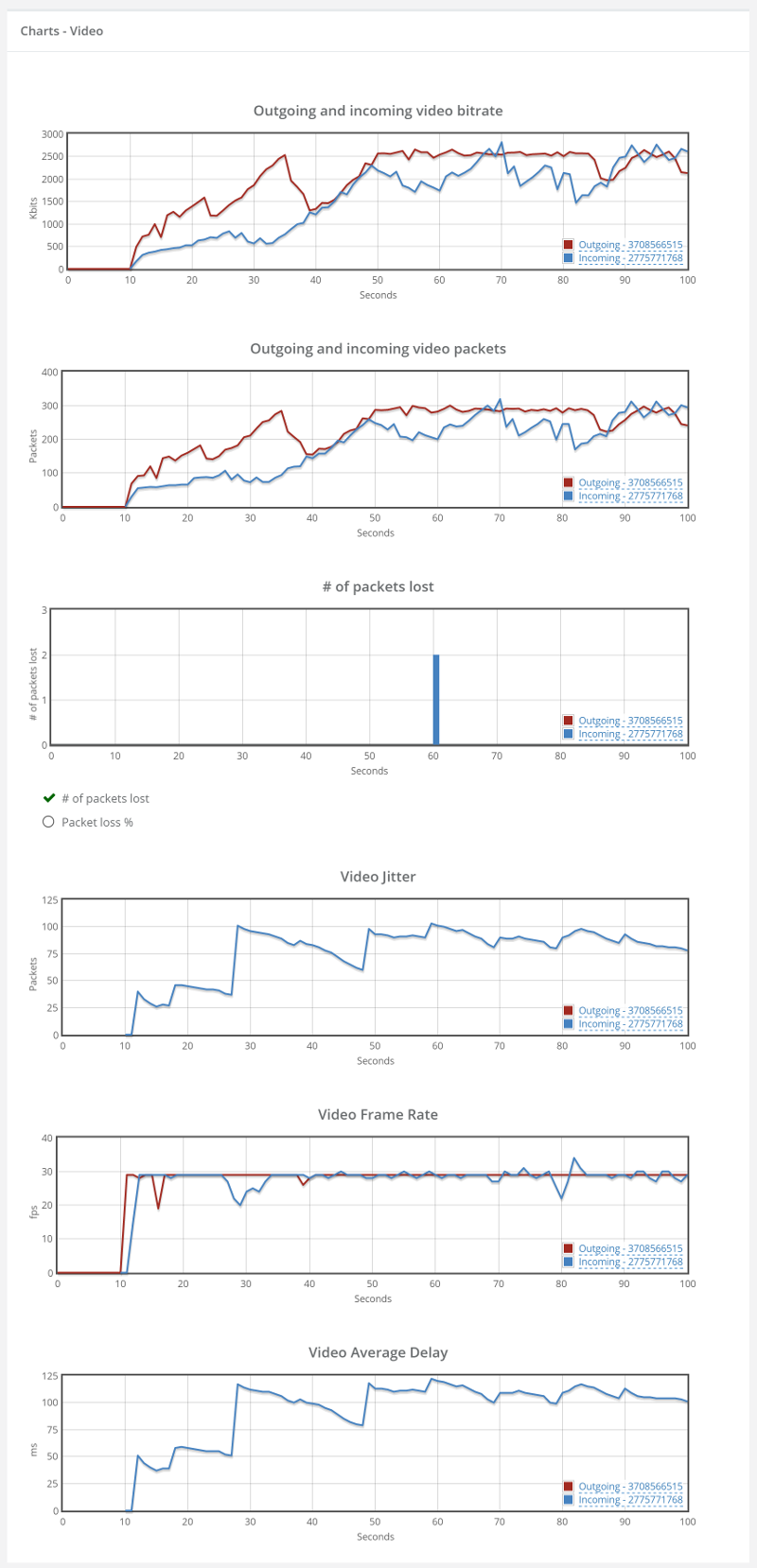 Things don’t really stabilize… at least not in a 90 seconds period of a session.
Things don’t really stabilize… at least not in a 90 seconds period of a session.