
You wouldn’t believe how TURN over TCP changes the behavior of WebRTC on the network.
I’ve written this on BlogGeek.me about the importance of using TURN and not relying on public IP addresses. What I didn’t cover in that article was how TURN over TCP changes the behavior we end up seeing on the network.
This is why I took the time to sit down with AppRTC (my usual go-to service for such examples), used a 1080p resolution camera input, configure my network around it using testRTC and check what happens in the final reports we get.
What I want to share here are 4 different network conditions:
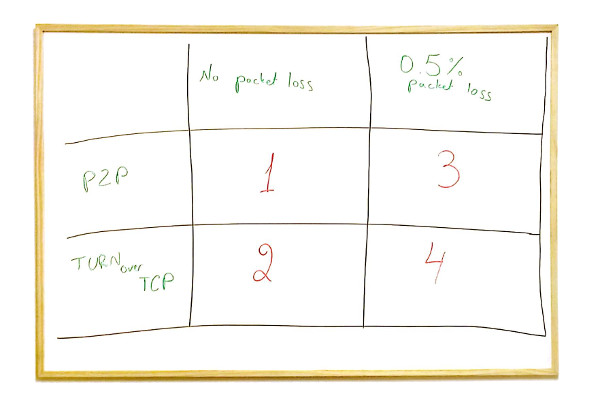
#1 – A P2P Call with No Packet Loss
Let’s first figure out the baseline for this comparison. This is going to be AppRTC, 1:1 call, with no network impairments and no use of TURN whatsoever.
Oh – and I forced the use of VP8 on all calls while at it. We will focus on the video stats, because there’s a lot more data in them.
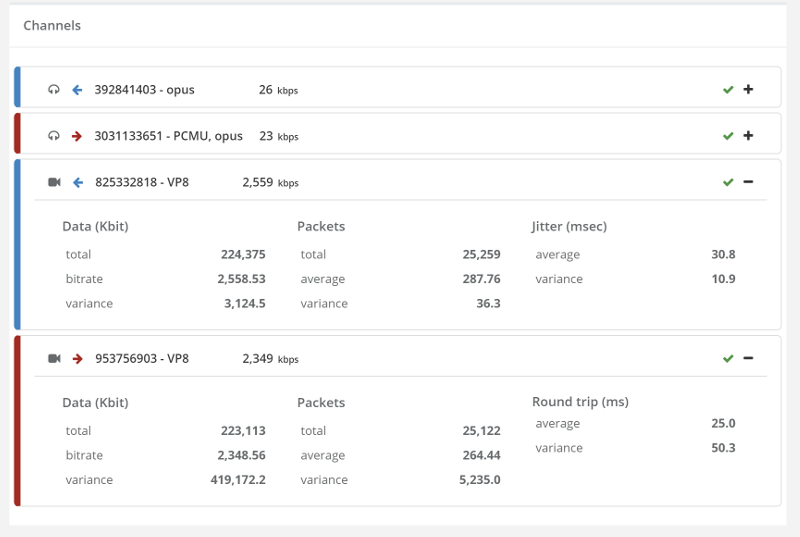
Our outgoing bitrate is around 2.5Mbps while the incoming one is around 2.3Mbps – it has to do with the timing of how we calculate things in testRTC. With longer calls, it would average at 2.5Mbps in both directions.
Here’s how the video graphs look like:
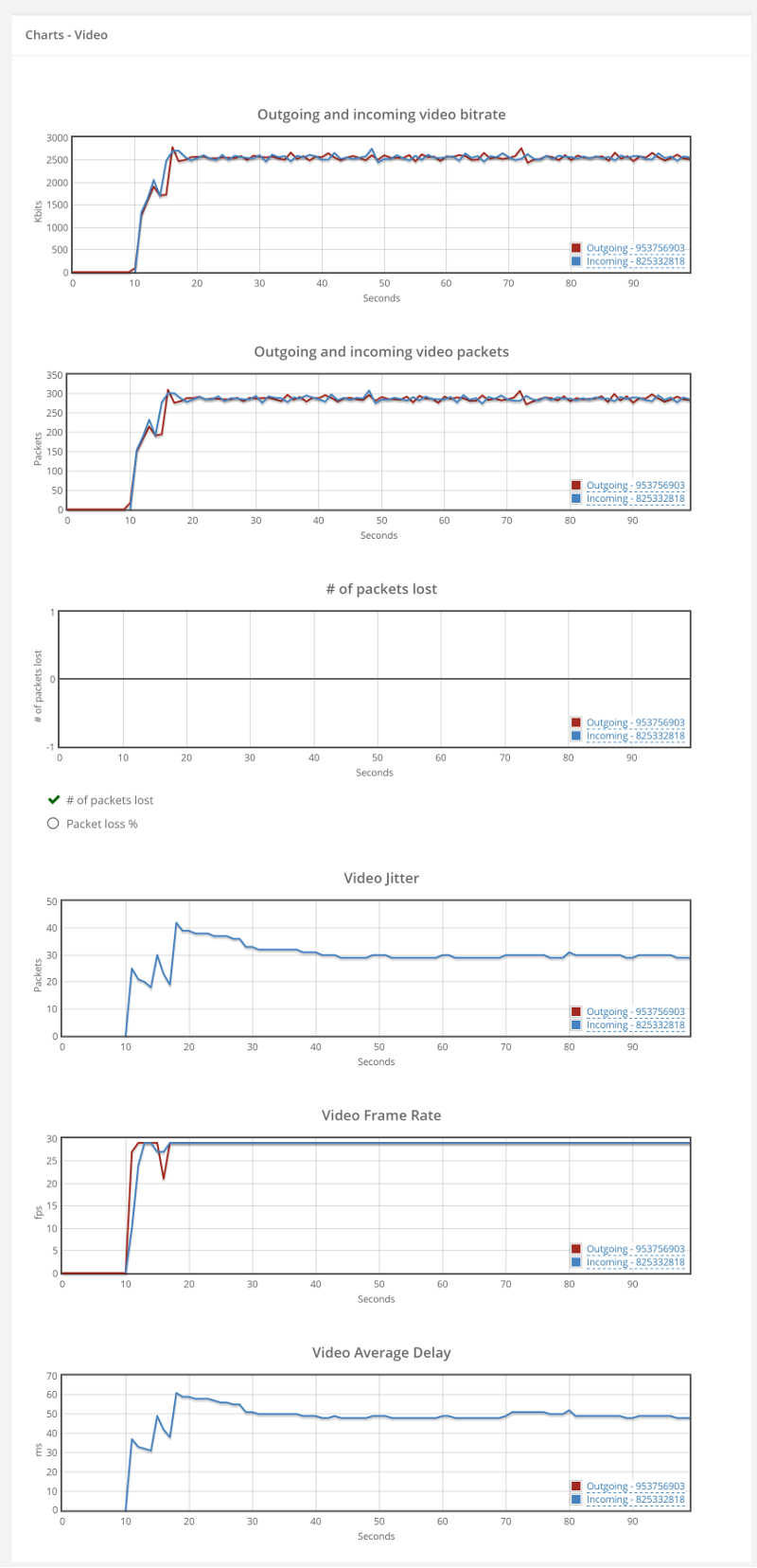
They are here for reference. Once we will analyze the other scenarios, we will refer back to this one.
What we will be interested in will mainly be bitrate, packet loss and delay graphs.
#2 – TURN over TCP call with No Packet Loss
At first glance, I was rather put down by the results I’ve seen on this one – until I dug into it a bit deeper. I forced TCP relay by blocking all UDP traffic in our machines.
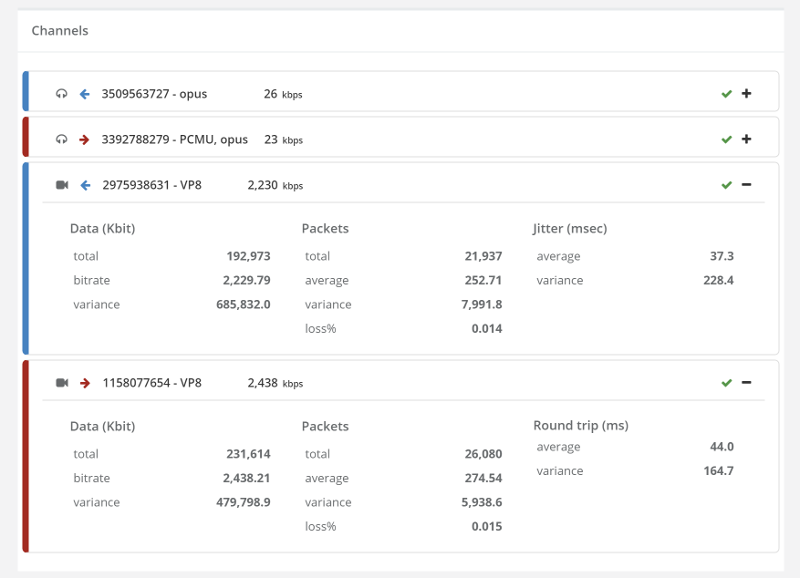
This time, we have slightly lower bitrates – in the vicinity of 2.4Mbps outgoing and 2.2Mbps incoming.
This can be related to the additional TURN leg, its network and configuration – or to the overhead introduced by using TCP for the media instead of UDP.
The average Round trip and Jitter vaues are slightly higher than those we had without the need for TURN over UDP – a price we’re paying for relaying the media (and using TCP).
The graphs show something interesting, but nothing to “write home about”:
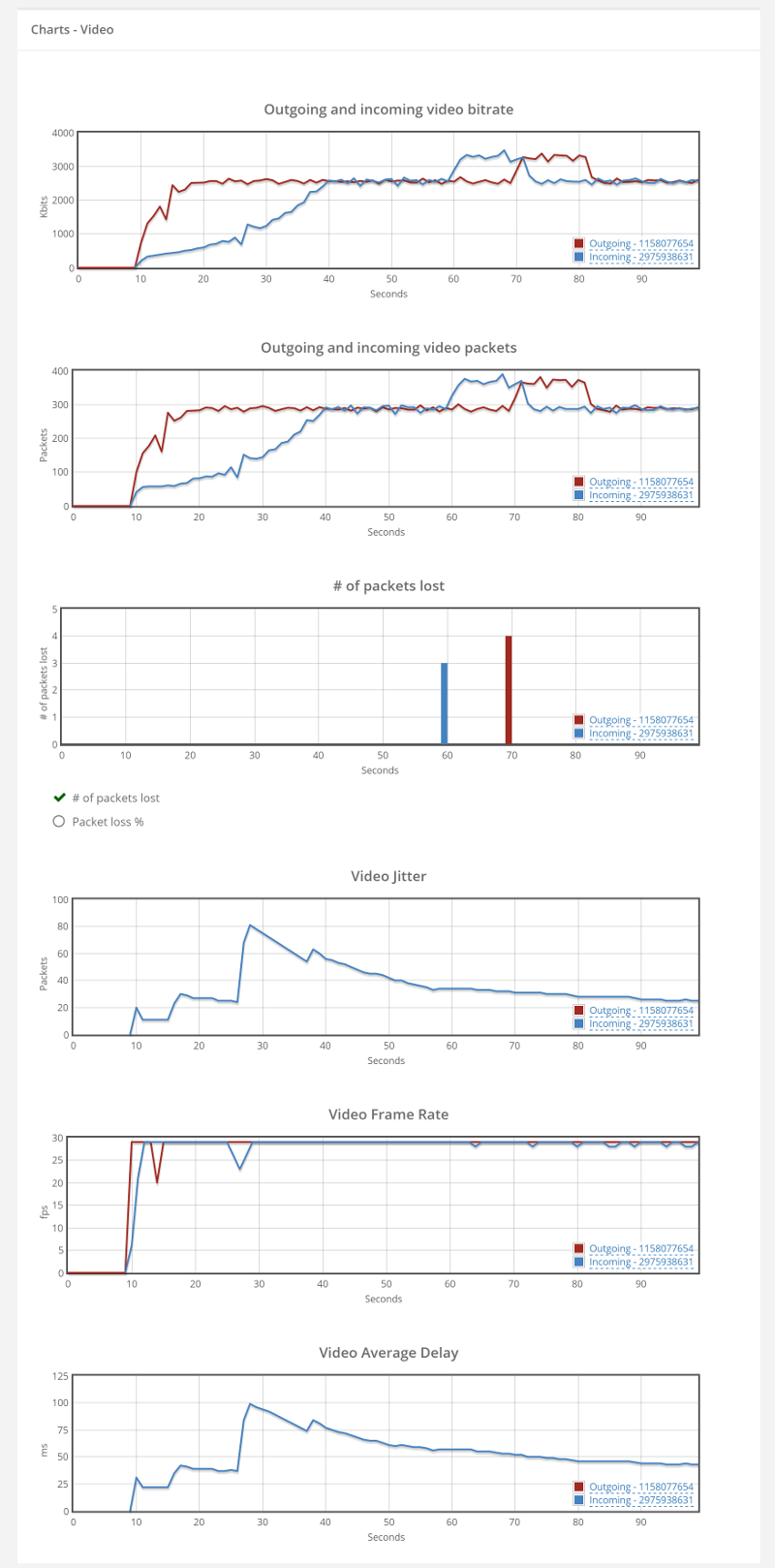
Lets look at the video bitrate first:
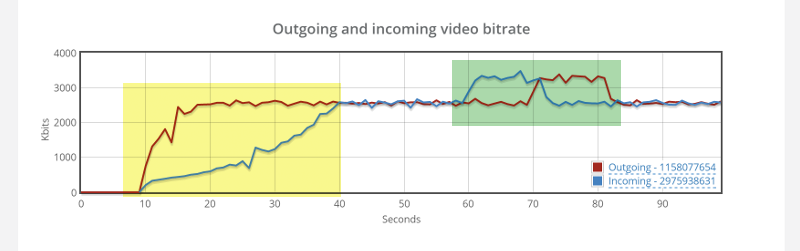
Look at the yellow part. Notice how the outgoing video bitrate ramps up a lot faster than the incoming video bitrate? Two reasons why this might be happening:
- WebRTC sends out data fast, but that same data gets clogged by the network driver – TCP waits before it sends it out, trying to be a good citizen. When UDP is used, WebRTC is a lot more agressive (and accurate) about estimating the available bitrate. So on the outgoing, WebRTC estimates that there’s enough bitrate to use, but then on the incoming, TCP slows everything down, ramping up to 2.4Mbps in 30 seconds instead of less than 5 that we’re used to by WebRTC
- The TURN server receives that data, but then somehow decides to send it out in a slower fashion for some unknown reason
I am leaning towards the first reason, but would love to understand the real reason if you know it.
The second interesting thing is the area in the green. That interesting “hump” we have for the video, where we have a jump of almost a full 1Mbps that goes back down later? That hump also coincides with packet loss reporting at the beginning of it – something that is weird as well – remember that TCP doesn’t lose packets – it re-transmits them.
This is most probably due to the fact that after bitstream got stabilized on the outgoing side, there’s the extra data we tried pushing into the channel that needs to pass through before we can continue. And if you have to ask – I tried a longer 5 minutes session. That hump didn’t appear again.
Last, but not least, we have the average delay graph. It peaks at 100ms and drops down to around 45ms.
To sum things up:
TURN over TCP causes WebRTC sessions to stabilize later on the available bitrate.
Until now, we’ve seen calls on clean traffic. What happens when we add some spice into the mix?
#3 – A P2P Call with 0.5% packet loss
What we’ll be doing in the next two sessions is simulate DSL connections, adding 0.5% packet loss. First, we go back to our P2P call – we’re not going to force TURN in any way.
Our bitrate skyrocketed. We’re now at over 3Mbps for the same type of content because of 0.5% packet loss. WebRTC saw the opportunity to pump more bits to deal with the network and so it did. And since we didn’t really limit it in this test – it took the right approach.
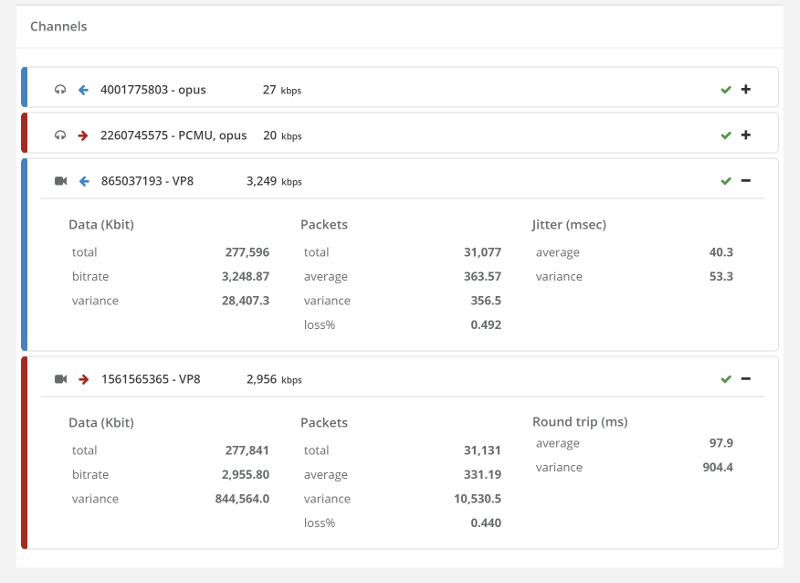
I double checked the screenshots of our media – they seemed just fine:

Lets dig a bit deeper into the video charts:
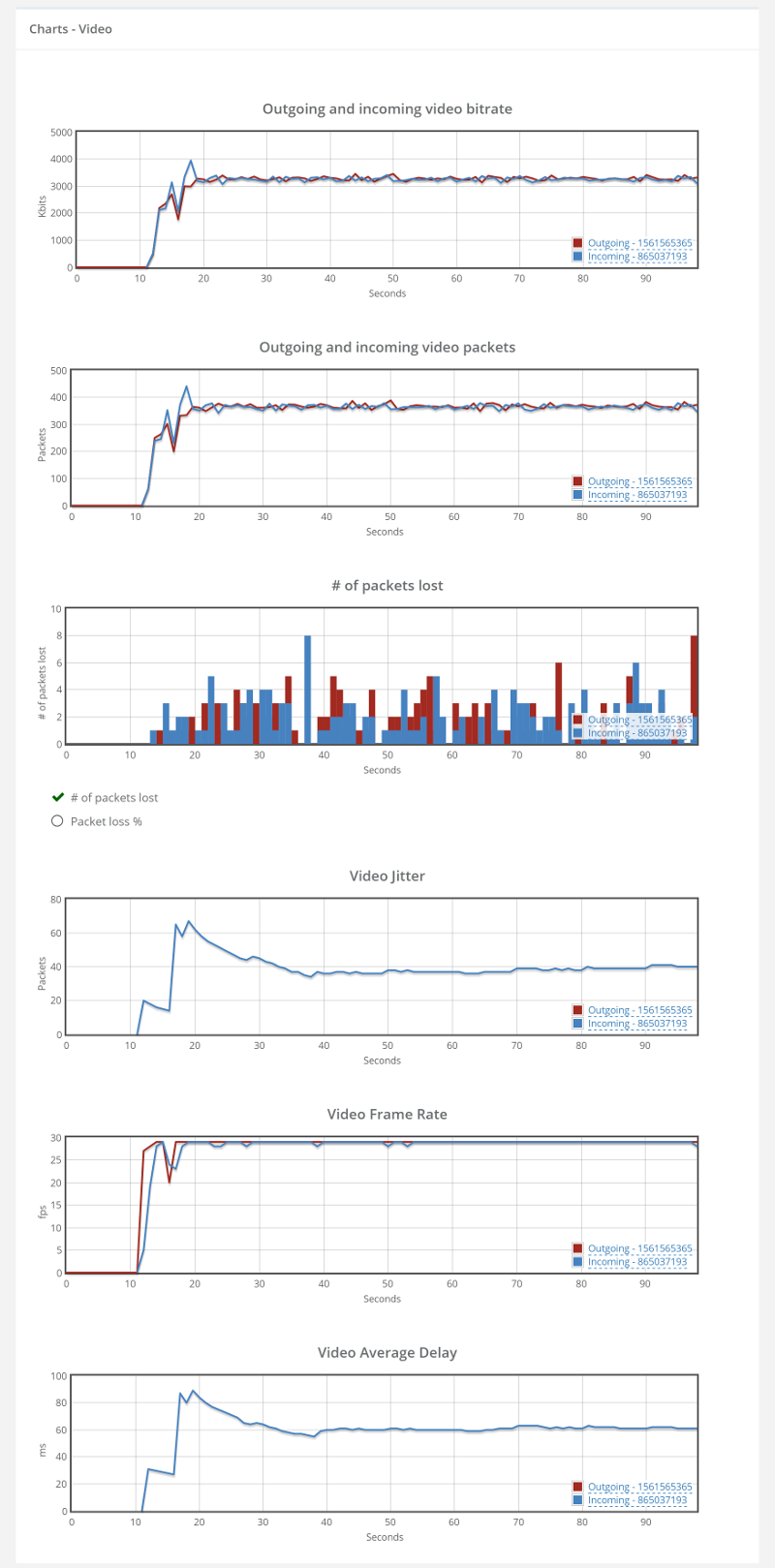
There’s packet loss alright, along with higher bitrates and slightly higher delay.
Remember these results for our final test scenario.
#4 – TURN over TCP Call with 0.5% packet loss
We now use the same configuration, but force TURN over TCP over the browsers.
Here’s what we got:
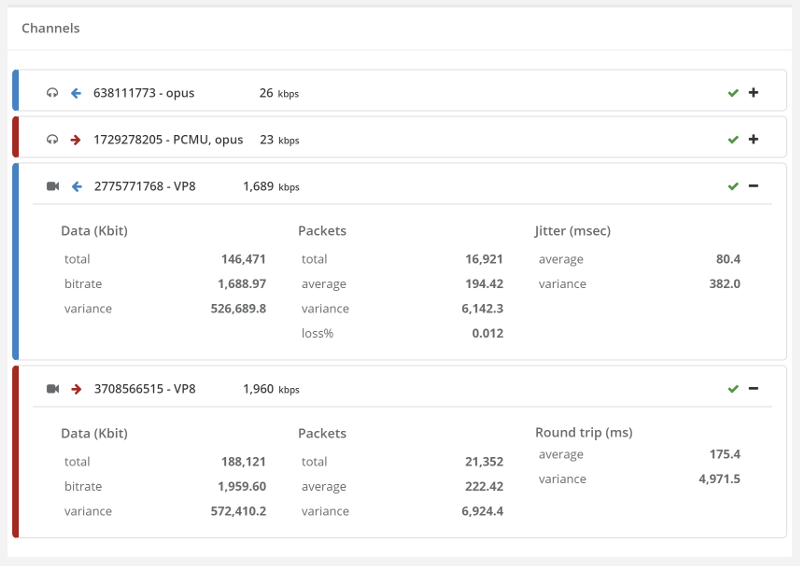
Bitrates are lower than 2Mbps, whereas on without forcing TURN they were at around 3Mbps.
Ugliness ensues when we glance at the video charts…
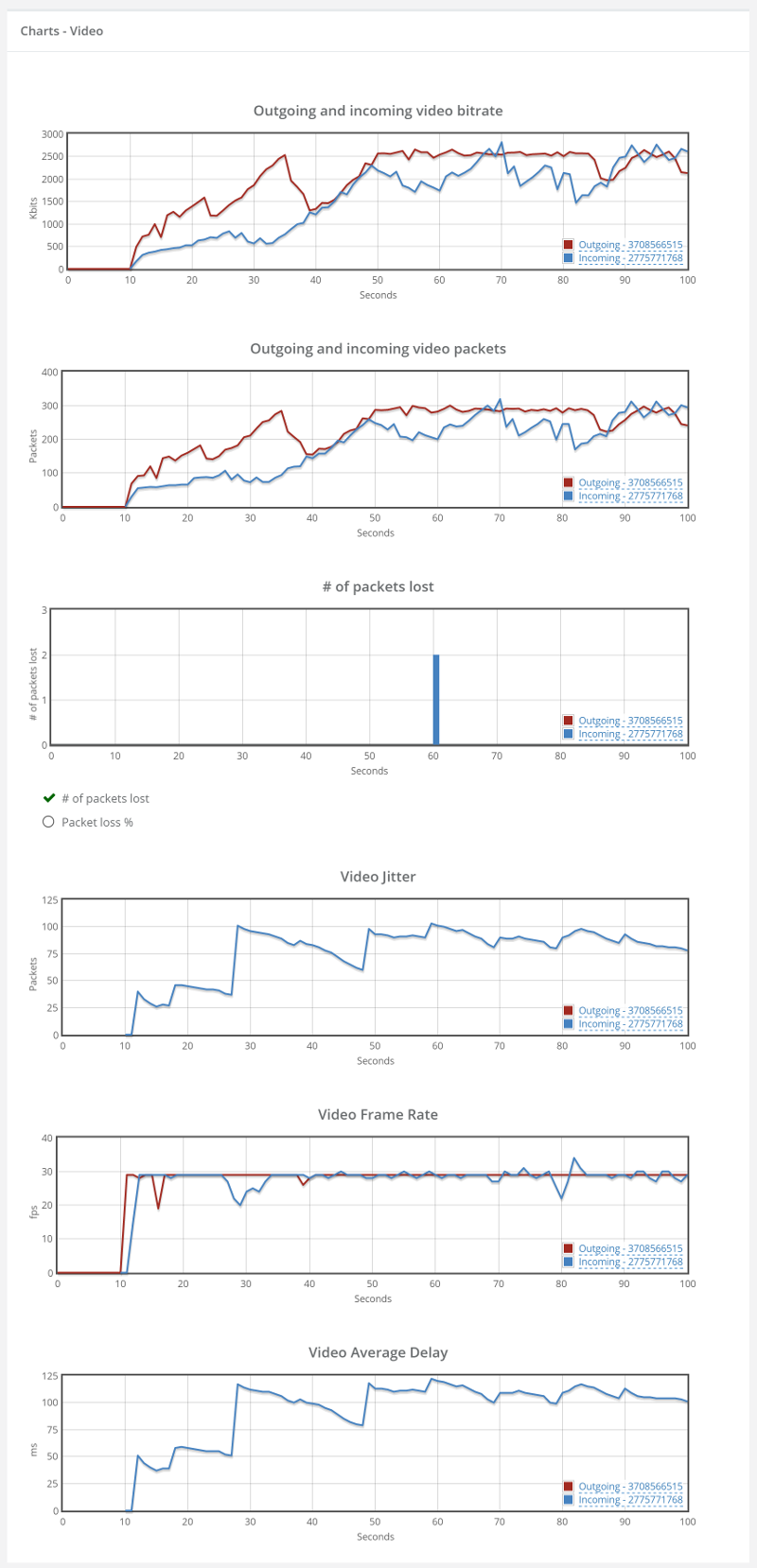 Things don’t really stabilize… at least not in a 90 seconds period of a session.
Things don’t really stabilize… at least not in a 90 seconds period of a session.
I guess it is mainly due to the nature of TCP and how it handles packet losses. Which brings me to the other thing – the packet loss chart seems especially “clean”. There are almost no packet losses. That’s because TCP hides that and re-transmit everything so as not to lose packets. It also means that we have utilization of bitrate that is way higher than the 1.9Mbps – it is just not available for WebRTC – and in most cases, these re-tramsnissions don’t really help WebRTC at all as they come too late to play them back anyway.
What did we see?
I’ll try to sum it in two sentences:
- TCP for WebRTC is a necessary evil
- You want to use it as little as possible
And if you are interested about the most likely ICE candidate to connect, then checkout Fippo’s latest data nerding post.