
Testing WebRTC is hard enough when you need to automate a single test scenario with two people in it, so doing things at scale means lots more headache.
We’ve noticed that in the past several months where more developers have started using our service to understand the capacity they can load on a single server. And as we do with all of our customers, we assisted them in setting up the scripts properly – it is still early days for us, so we make it a point to learn from these interactions.
What we immediately noticed is, that while our existing mechanisms for synchronization can be used – they should be used slightly differently because at scale the problems are also different.
How do you synchronize with testRTC?
There are two main mechanisms in testRTC to synchronize tests, and we use them together.
What we do is think of a test run as a collection of sessions. Each session has its own group of agents/browsers who make up that session. And inside each such session group – you can share values across the agents.
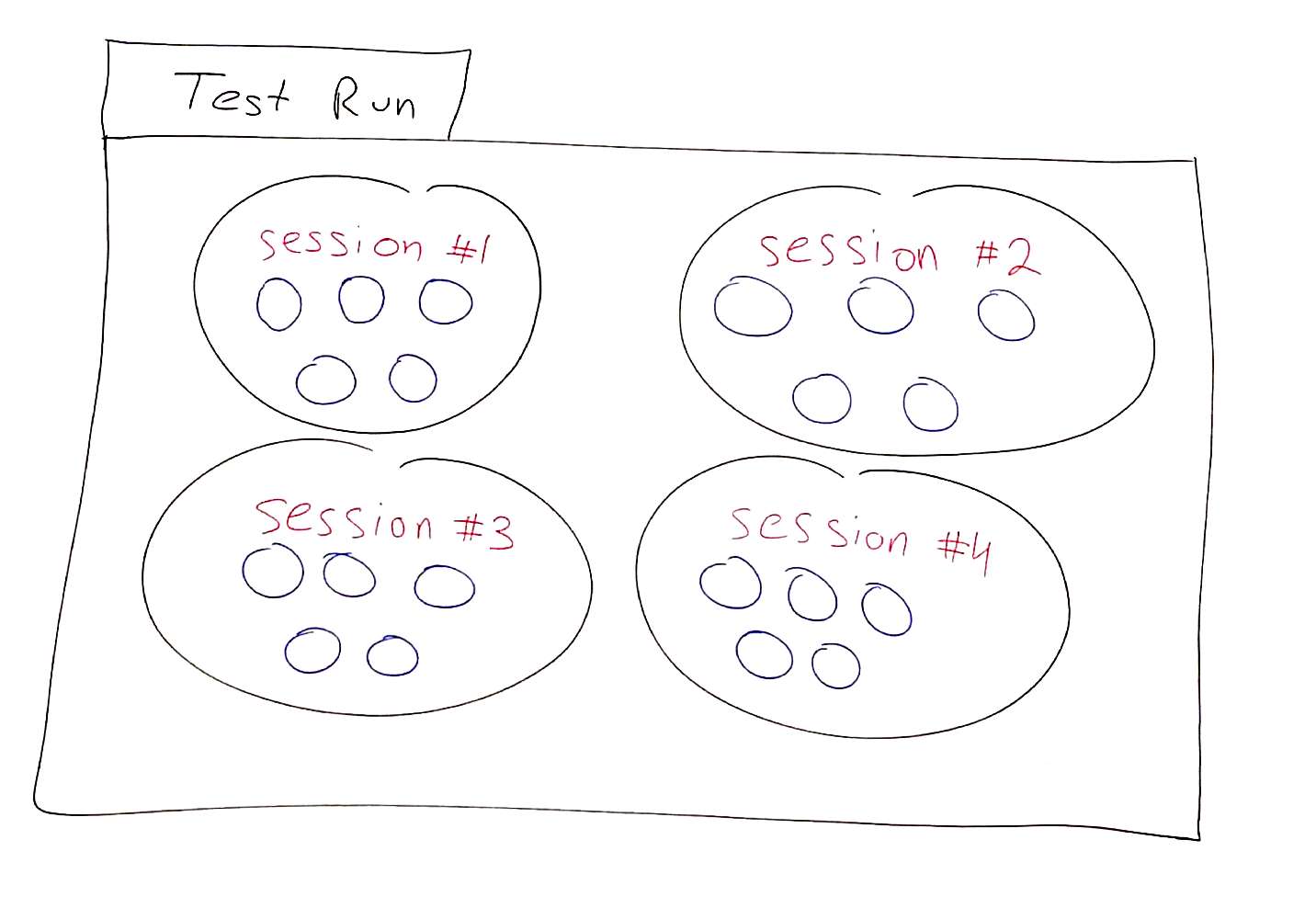
So if we want to try and do a test run for our WebRTC service similar to the above – 4 video conference calls of 5 browsers in each call, we configure it the following way in testRTC:

While this is all nice and peachy, let’s assume that in order to initiate a video conference, we need someone in each group of 5 browsers to be the first to do *something*. It can be setting up the conference, getting a random URL – whatever.
This is why we’ve added the session values mechanism. With it, one agent (=browser) inside the session, can share a specific value with all other agents in his session – and agents can wait to receive such a value and act upon it.
Here’s how it looks like for a testRTC agent to announce it logged in and is ready to accept an incoming call for example:

We decided arbitrarily to call our session key “readyForCall”, and we used an arbitrary value of “ignore” just because.
On the ‘receiving’ end here, we use the following code:
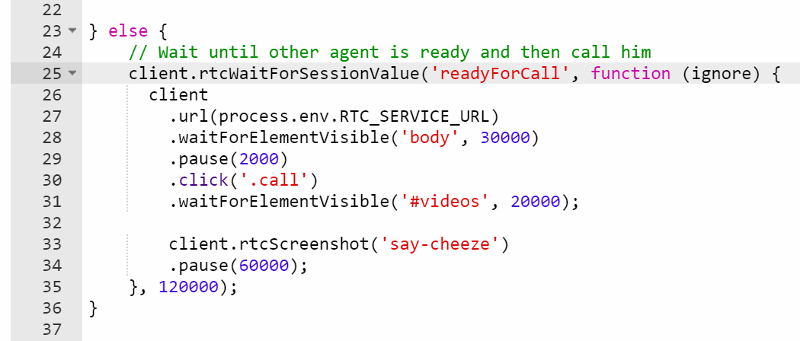
So now we have the second browser in the session waiting to get a value for “readyForCall”, and in this simple case, ignore the value and click the “.call” button in the UI.
This technique is something we use all the time in most of the scripts these days to get agents to synchronize their actions properly.
How do we scale a WebRTC test up?
The neat thing about these session values is that they are get signaled around only within the same session. So if we plan and write our test script properly, we can build a single simple session where browsers interact with each other, and then scale it up by increasing the size of the session to what we want and the size of the concurrent agents in the test run.
With our video conferencing service, we start with a 3-way session, using 3 agents. We designate agent #1 in the session as our “leader”, who must be the first to login and setup the session. Once done, he sends the URL as a session value to the other agents in the session.
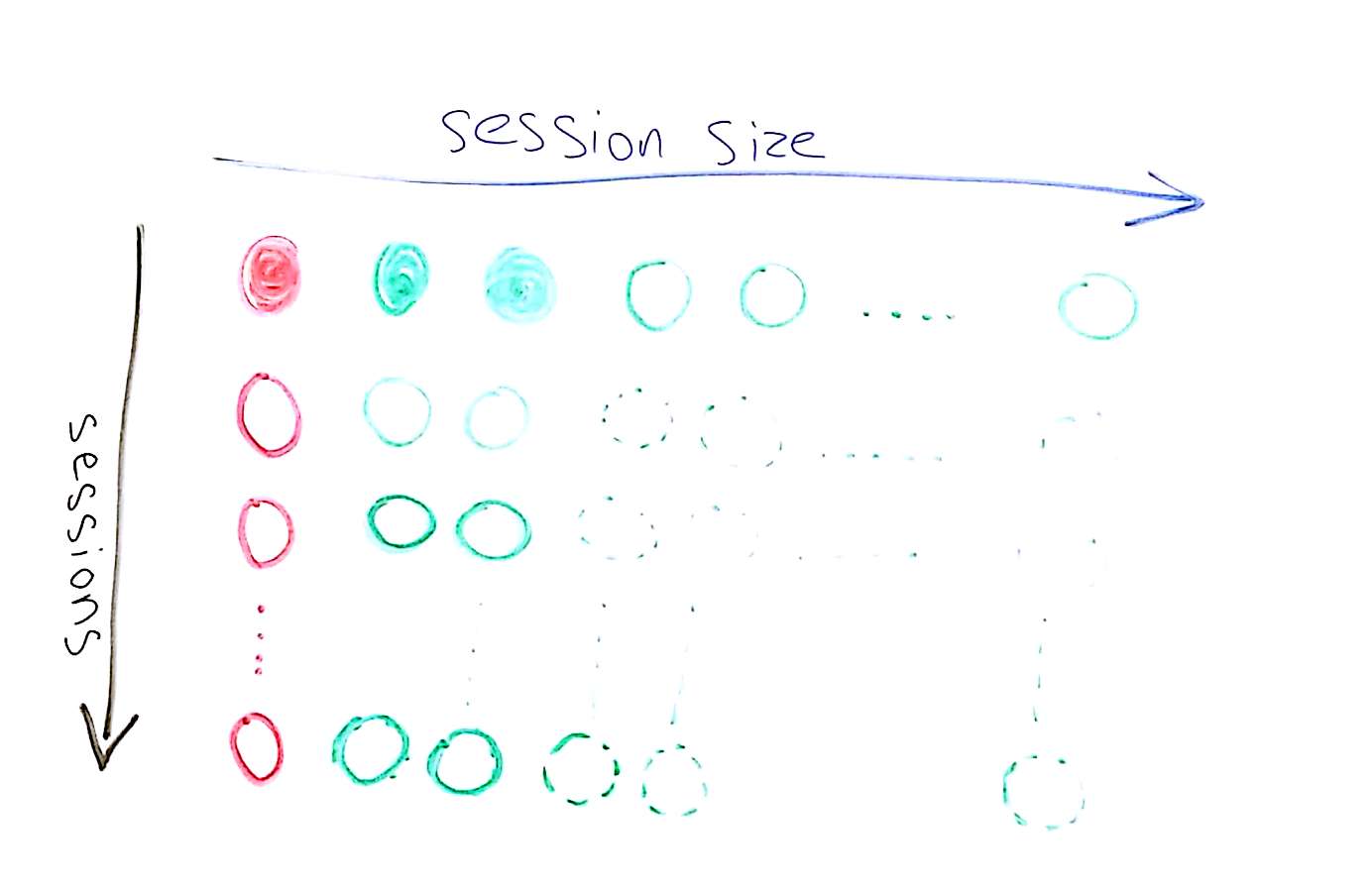
The moment we want to scale that test up, we can grow the session size to 5, 10, 20, 100 or more. And when we want to check multiple video conferences in parallel, we can just grow the number of concurrent agents in the test run but leave the session size smaller.
A typical configuration for several test runs of scale tests will look like this:
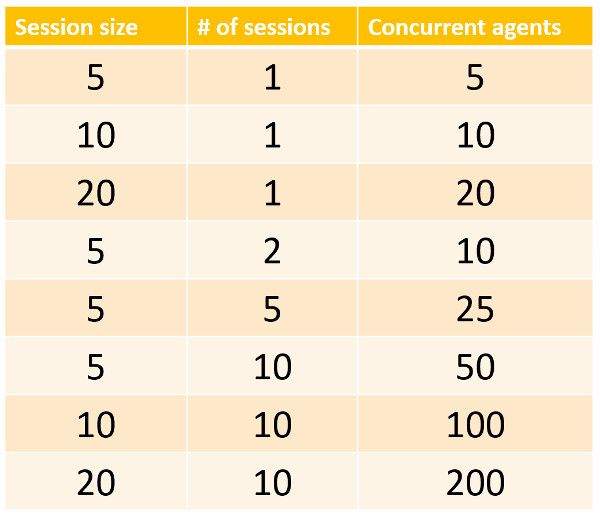
- Start with 5 agents in a single session
- Then run 10 agents in 2 sessions (5 agents per session)
- …
- End with 200 agents in 10 sessions (20 agents per session)
What will usually go wrong as we scale our WebRTC scenario?
Loads of things. Mainly… load.
We’ve seen servers that break down due to poor network connection. Or maxed out CPU. Or I/O as they store logs (or media recordings) to the disk. And bad implementations and configurations. You name it.
There are though, a few issues that seem to plague most (all?) WebRTC based services out there. And the main one of them is that they hate a hoard logging in at roughly the same time.
That just kills them.
You take 20 browsers. Point them all to the same URL, in order to join the same session, and you get them to try it out all together in the span of less than a second. And things fall down in pieces.
I am not sure why, but I have my own doubts and ideas here (something to do with the way RTCPeerConnection is used to maintain these media streams and how the SFUs manage it internally in their own crazy state machine). Now, for the most part, customers don’t care. Because this usually won’t happen in real life. And if it does – the user will hit F5 to refresh his browser and the world will get back to normalcy for him. So it gets lower priority.
Which leads us again to synchronization issues. How can we almost un-synchronize browsers and have them NOT join together, or at least have them join “slower”?
We’ve devised a few techniques that we are using with our customers, so we wanted to share them here. I’ll call them our 3 synchronization techniques for testing WebRTC at scale.
Here they are.
#1 – Real-users-join-randomly
This is as obvious as it gets.
If we have 10 users that need to enter the same session, then in real-life they won’t be joining at the exact same time. Our browsers do. So what do you do? You randomize having them join.
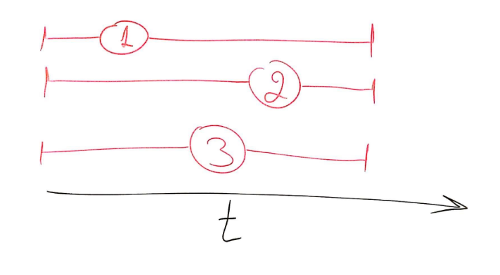
For 3 browsers, we have them all join “at the same time”, we just spread it around a bit – just like in the illustration below, where you can see in the red lines where each browser decided to join:
Here’s how we usually achieve that in testRTC:

#2 – Pace-them-into-the-service technique
Random doesn’t always cut it for everyone. This becomes an issue when you have 100 or more browsers you want to load the server with. I am not sure why that is, as it has nothing to do with how testRTC operates (how do I know this? Using the same test on something like AppRTC with no pacing works perfectly well), but again – developers are usually too busy to look at these issues in most of the scenarios that we’ve seen.
The workaround is to have these browsers “walk in” to the room roughly one after the other, at a given interval.
Something like this:
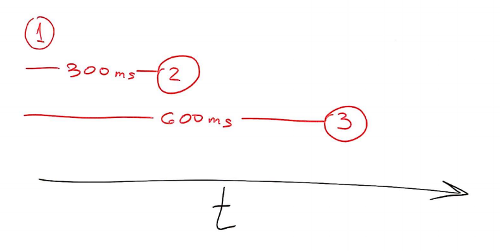
Here, what we do is pacing the browsers to join in a 300 milliseconds interval from one another. The script to it will be similar to this:

This is a rather easy method we use a lot, but sometimes it doesn’t fit. This occurs when timing can get jumbled due to network and other backend shenanigans of services.
#3 – One-after-the-other technique
Which is why we use this one-after-the-other technique.
This one is slightly more difficult to implement, so we use it only when necessary. Which is when the delay we wish to create doesn’t sit at the beginning of the test, but rather after some asynchronous action needs to take place – like logging in, or waiting for one of the browsers to create the actual meeting place.
The idea here is that we let each browser join only after another one in the list as already joined. We create a kind of a dependency between them using the testRTC synchronization commands. This is what we are trying to achieve here:
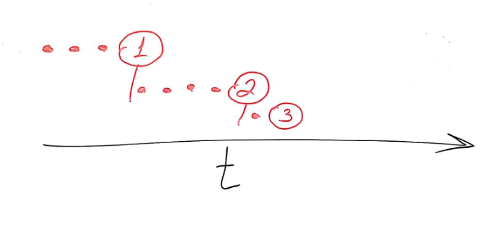
So we don’t really care how much time each browser takes to finish his action – we just want to make sure they join in an orderly fashion.
Usually we do that from the last browser in the session down to the first. There are three reasons why:
- It looks a lot smarter – like we know what we’re doing – so my ego demands it
- It makes it easier to scale a session up, since we’re counting down the numbers down to zero
- We can stop in the middle easily, if we have different types of browsers in the same session
Here’s how the code for it looks like:
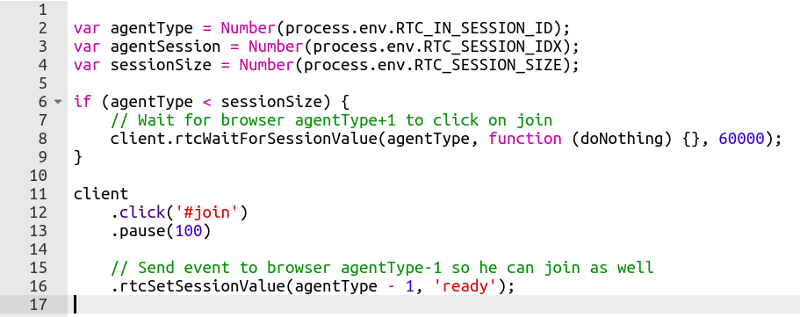
Here, what happens is this:
- agentType holds the index number of the running browser inside the session
- sessionSize holds the number of browsers in a single session
- If we are not the last browser in the session, then we wait until the next browser tells us he is ready (line 8). When he does, we join (line 12) and then we tell the previous browser in line that we are ready (line 16)
- If we are the last browser, we just join and tell the previous one that we’re ready
A bit more complex, so we save it for when it is really necessary.
What’s next?
Here’s what we’ve learned:
- We use session and session values for synchronization and scale purposes
- We split a test run into group of browsers, designated to their own sessions
- Inside a session, we can give different roles to different browsers
- This enables us to pick and choose the size of a session and the size of a test run easily
- In most cases, large sessions don’t like browsers joining all at once – it breaks most services out there (and somehow, developers are fine with it)
- There are different ways to get testRTC to mimic real life when needed. Different techniques support different scenarios
If you are planning on stress testing your WebRTC service – and you probably will be at some point in time, then come check us out. Here are a few of the questions we can answer for you:
- How many users can I cram into a single session/room/conference without degrading quality?
- How many users can a single media server I have support?
- How many parallel sessions/rooms/conferences can a single media server I have support?
- What happens when my service needs to scale horizontally? Is there any degradation for the users?
Partial list, but a good starting point. See you in our service!