
Here’s a question we come across quite often at testRTC.
You decided to self develop your own service. Manage your own media servers. And now that time comes to understand your ongoing costs as well as decide on the scale out scheme – at what point do you launch/spawn a new server to take up some of the load from your current media servers farm? How many users can you cram into a single media server anyway?
We decided to check just that, doing it with the help of WebRTC.ventures who worked with us on the setup.
For the purpose of these set of sizing experiments, we picked up Kurento, one of the most versatile open source media servers out there today. We selected a few key scenarios, and WebRTC.ventures installed the server and configured it for us.
We then used our testRTC probes to understand how many users can we cram on the server in each scenario.
Simple scenario sizing is one step in the process. If you are serious about your service, then check out our best practices to stress testing your WebRTC application.
Why Kurento?
There are a couple of reasons why we picked Kurento for this one.
- Because many use it out there, and we’ve been helping customers understand and debug it when they needed to
- It is versatile. We could try multiple scenarios with it with relative ease and little programming (although that wasn’t our part of the project)
- It does media processing beyond just routing media. We wanted to see how this will affect the numbers, especially considering the last reason below
- It’s the first of a few media servers we’re going to play with, so stay with us on this one
The Scenarios
For the Kurento service, we picked up 3 different scenarios we wanted to test:
- 1:1 video calls. A typical doctor visitation or similar scenario, where two participants join the same session and the session gets recorded (two separate streams, one for each participant).
- 4-way group video calls. The classic scenario, in an MCU configuration. Kurento decodes and encodes all media streams, so we’re giving it quite a workout
- Live broadcast. A single person talking to a large group of viewers.
For scenarios (1) and (2) our question is how many concurrent sessions can the Kurento server hold.
For scenario (3) our question is how many viewers for a single broadcast can the Kurento server hold.
The Setup
To set things up for our test, we did the following:
- We went for a simple AWS t2.medium machine, but quickly had to switch to a more capable machine. We ended up with a c4.2xlarge instance (8 vCPU, 15 GB RAM) on AWS
- We had it monitored via New Relic, to be able to check the metrics (but later decided to forgo this approach and just use top with root access directly on the machine)
- We also had an easy way to reset the Kurento server. We knew that rattling it too much between tests without a reset would affect our results. We wanted a clean slate each time we started
The machine was hosted in Amazon US-East.
testRTC probes were coming in from a different cloud vendor, East and West US locations.
We didn’t do any TURN related stuff – so our browser traffic hit the Kurento server directly and over UDP.
The Process
For each scenario, we’ve written a simple test script that can scale nicely.
We then executed the test script in its minimal size.
For 1:1 video calls and broadcasts we used 2 probes and for the 4-way group video call we started with 4 probes.
We ran each test for a period of 4-5 minutes, to check the stability of the media flow.
We used that as the baseline of our results and monitored to see when adding more probes caused the media metrics to start faltering.
1:1 Video Calls
The above screenshot is what you’ll see if you participated in these sessions. There’s a picture in picture view of the session, where the full screen area is the remote incoming video and the smaller window holds our local view.
Baseline
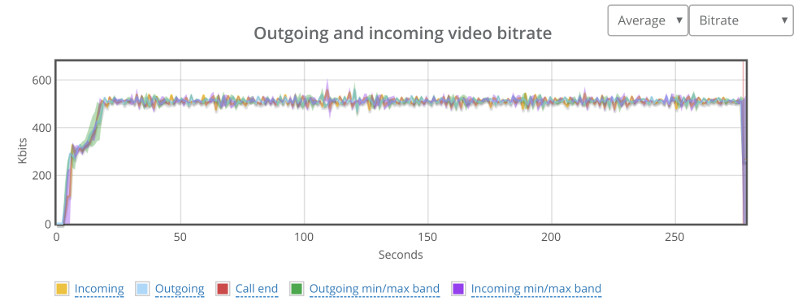
Kurento’s basic configuration limits bitrate of calls to around 500kbps. This can be seen from running a single session in our high level chart:
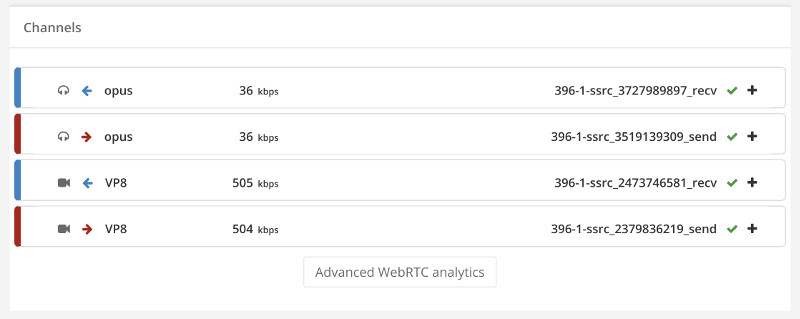
And here’s the stats on the channels of one of the two probes in this baseline test run:
Now that we have our baseline, it was time to scale things up.
30 Probes (=15 sessions)
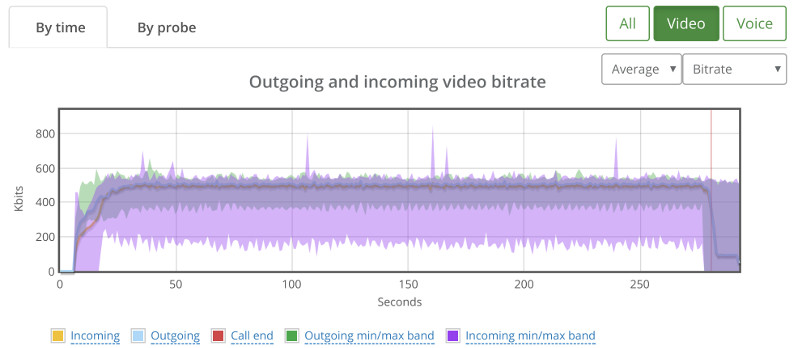
When we went up to 30 probes, running in 15 parallel 1:1 video sessions, we ended up with this graph:
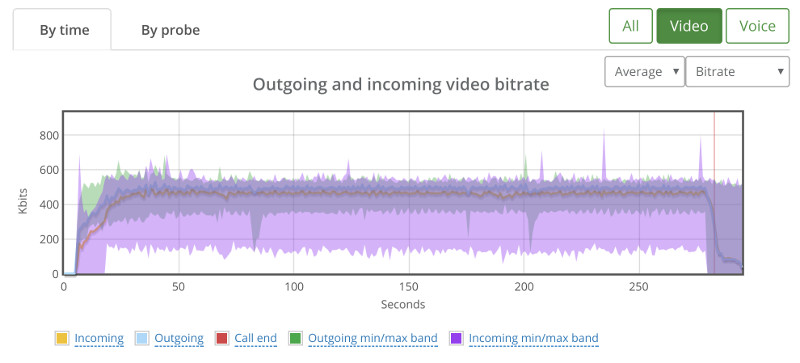
While the average bitrate is still around 500kbps, we can see that the min/max bands are not as stable.
If we look at the packet loss graph, things aren’t happy (the baseline had no packet losses):
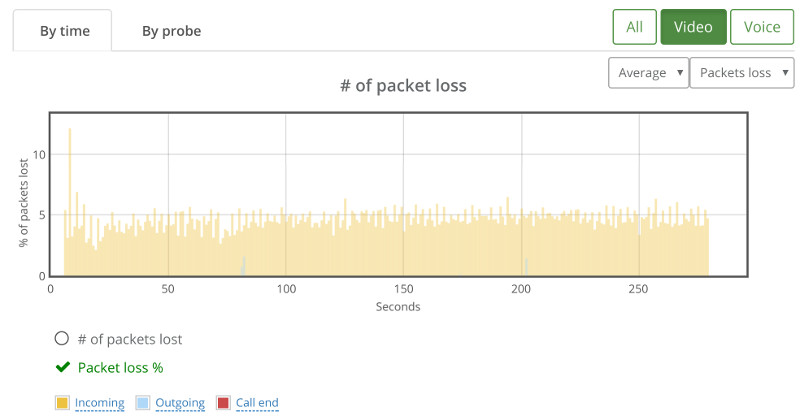
This is where we went for the “By probe” tab, looking at individual bitrates across the probes:
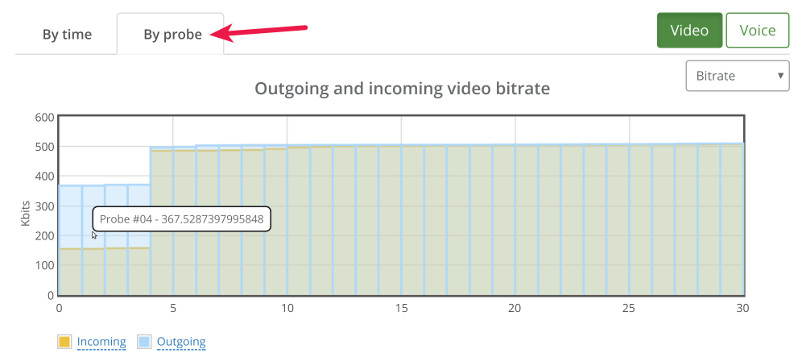
What we can see immediately is that 4 probes out of 30 didn’t get the full attention of the Kurento media server – they got to send and receive less than 500kbps.
If we switch to the packet loss by probe, we see this:
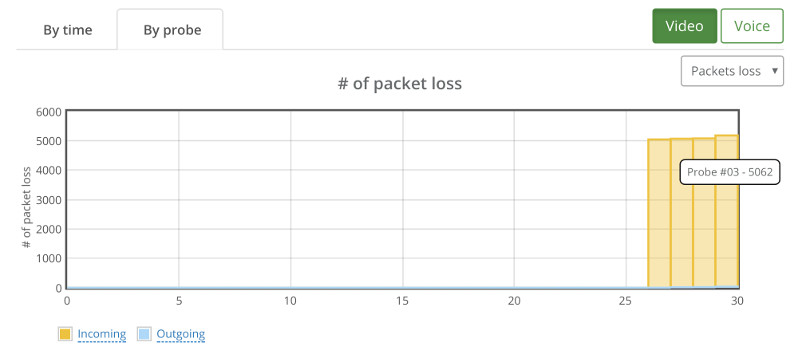
A couple of things that come to mind:
- Kurento degrades quality to specific sessions and not across the board. Out of 30 users, 22 got the expected results, 4 had lower bitrates and another 4 had packet losses
- There’s correlation here. When Probe #04 exhibits reduction in bitrate, Probe #3 reports incoming packet losses
From here, we can easily go down the path of drilling down to the probes that showed issues. I won’t do it now, as there’s still a lot to cover.
22 Probes (=11 sessions)
It stands to reason then that lowering the capacity to 22 probes should give us pristine results.
Here’s what we’ve seen instead:
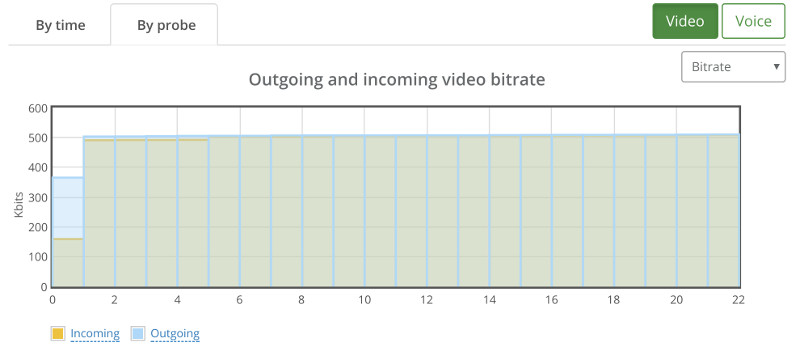
We still have that one session that goes bad.
20 or 18?
When we went down to 18 or 20 probes, things got better.
With 20 the issue is that we couldn’t really reproduce a good result at all times. Sometimes, the scenario worked, and other times, it looked like the issues we’ve seen with the 22 probes.
18 though seemed rather stable when tested a couple of times:
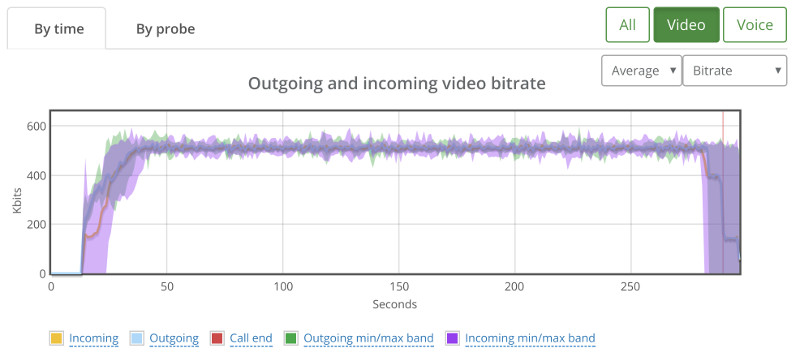
Depending on the service you’re offering, I’d pick 18. Or even go down to 16…
4-Way Group Video Calls
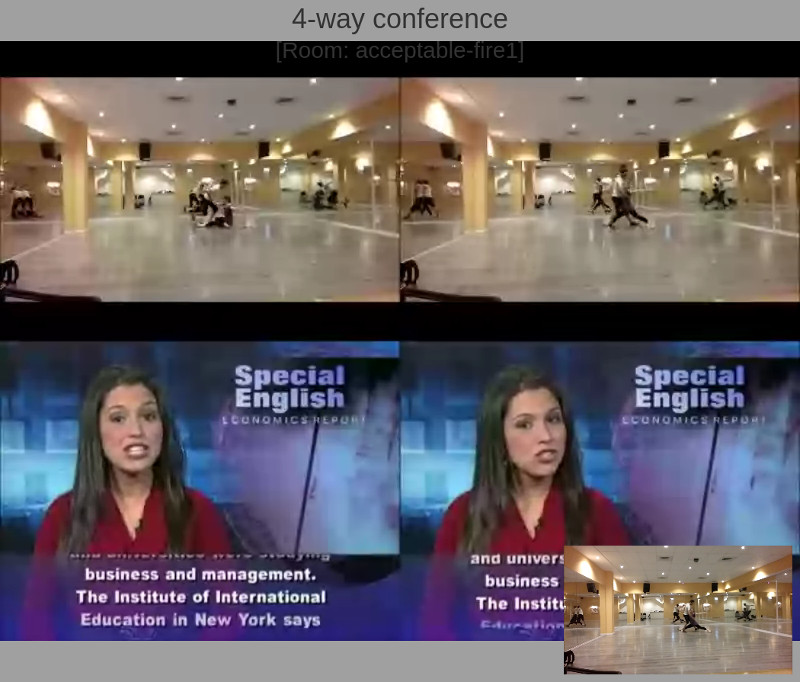
The above is a screen capture of the 4-way group video call scenario we’ve analyzed.
In this case, each probe (browser) sends out video at a resolution of 640×360 and receives a video resolution of 800×600.
The screenshot doesn’t show the images getting cropped, so we can assume the Kurento media server takes the following approach to its pipeline:
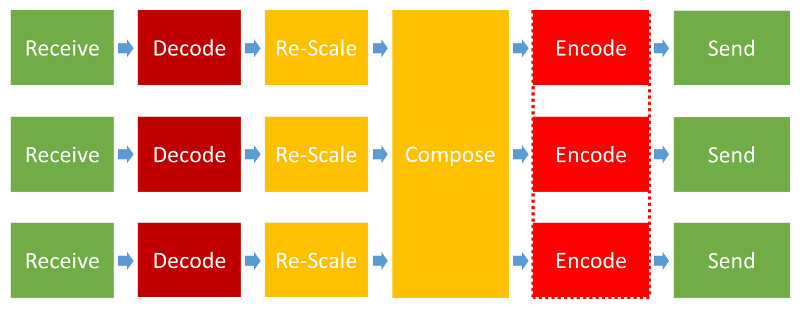
That’s lots of processing needed for each probe added, which means we can expect lower scaling for this scenario.
Baseline
Our baseline this time is going to need 4 probes.
Here’s high the high level video graph looks like:
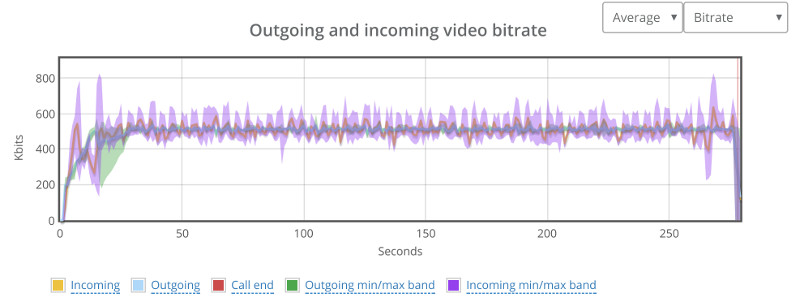
Not as stable as our 1:1 video calls, but it should do for what’s coming.
Note that each probe still has around 500kbps of video bitrate.
I’ll skip the drill down into the results of a specific probe metrics and take this as our baseline.
20 Probes (=5 sessions)
Since 1:1 video sessions didn’t go well above 20, we started there and went down.
Here’s how 20 probes look like:
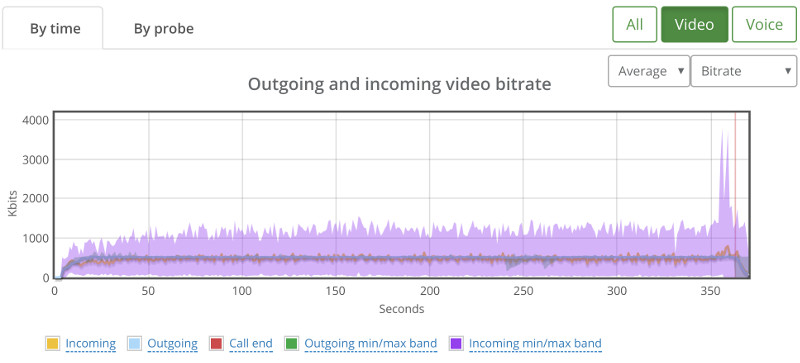
Erratic.
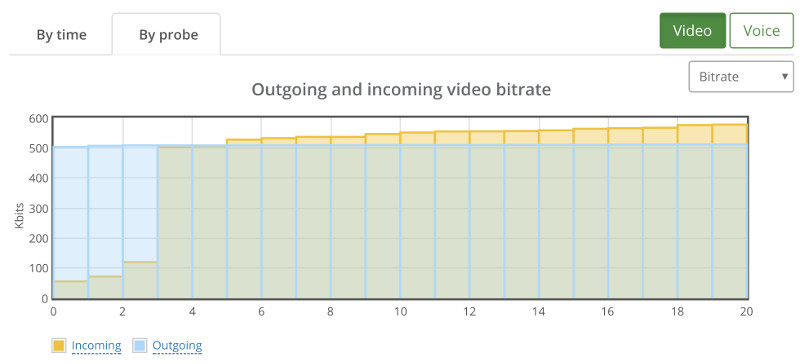
Checking packet losses and bitrates by probe yielded similar results to the bad 1:1 sessions. Here’s the by probe bitrate graph:
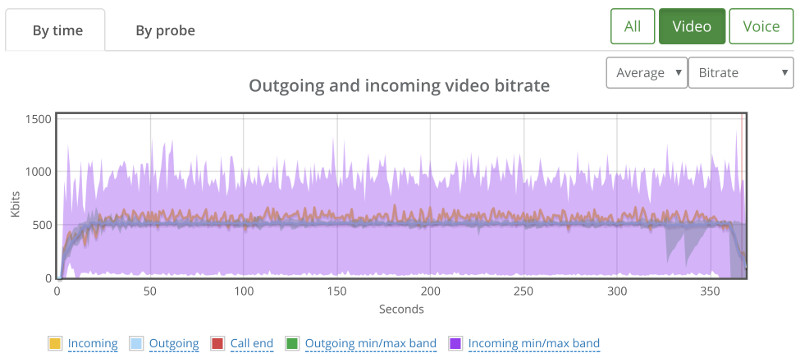
Going down to 16 probes (=4 sessions) wasn’t any better:
I’ve actually looked at the bitrates and packet losses by probe, and then decided to map them out into the sessions we had:
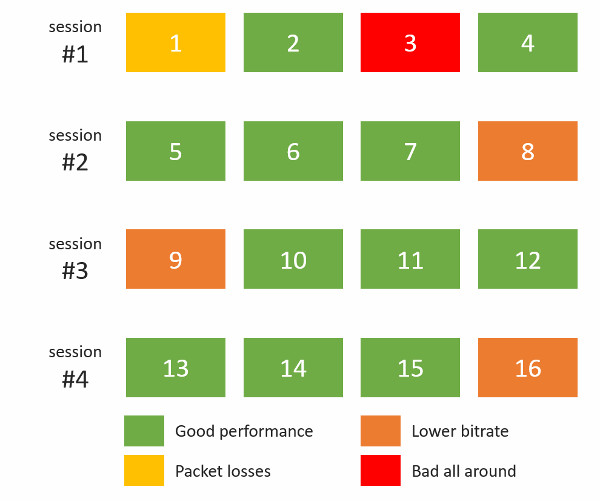
This paints a rather grim picture – all 4 sessions hosted on the Kurento server suffered in one way or another. Somehow, the bad behavior wasn’t limited to one session, but showed itself on all of them.
Down to 12 Probes (=3 sessions)
We ended up with 12 probes showing this high level bitrate graph:
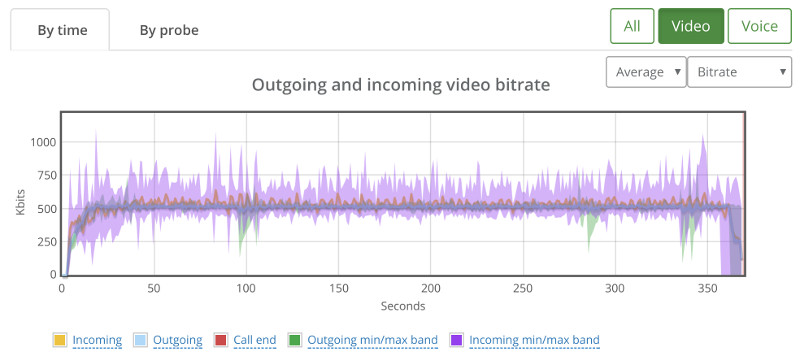
It showed some sporadic packet losses that were spread across 3 different probes. The following shows the high level by probe bitrate graph:
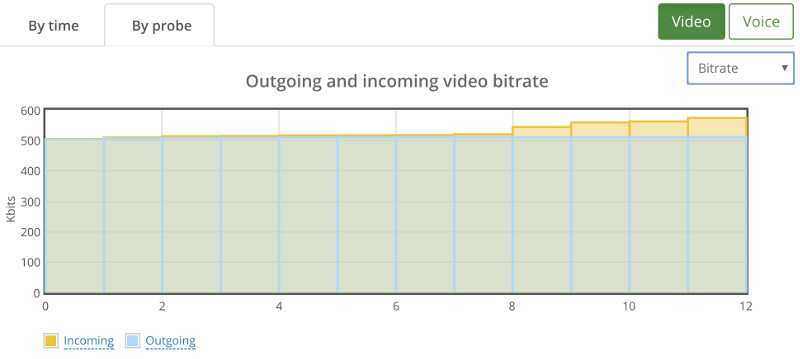
There’s some instability in the bitrates and the packet losses which will need some further investigation, but this is probably something we can work with and try and optimize our service to run well.
Live Broadcast

The above screenshot shows what a viewer sees on a live broadcast scenario that we’ve set up using Kurento.
We’ve got multiple testRTC probes joining the same broadcast, with the first one acting as the broadcaster and the rest are just viewers.
Baseline
Our baseline this time is going to need 2 probes. A broadcaster and a viewer.
From now on, we’ll be focusing on what the viewers experience – a lot more than what happens to the broadcaster.
We’re still in the domain of 500kbps for the video channel:
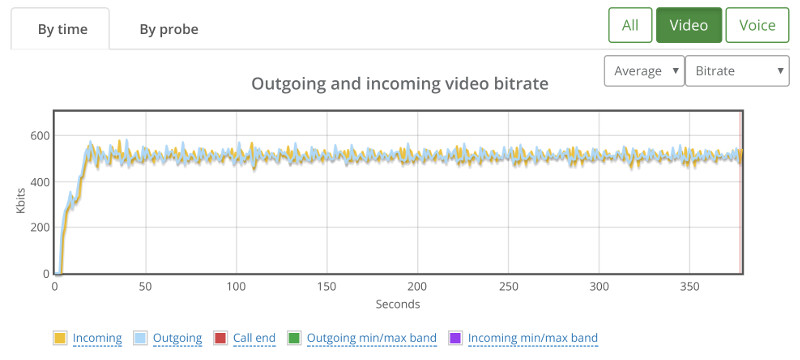
One thing to remember here – outgoing media happens only for our broadcaster probe and incoming media happens for all the other probes.
30 Probe (=29 viewers)
We started with 30 probes – assuming we will fail miserably based on our previous tests, and got positively surprised:

Solid bitrate for this test.
Climbing up
We’ve then started moving up with the numbers.
50, 60 and 80 probes went really well.
Got our appetite, and jumped towards 150 probes.
And ended up with this high level graph:
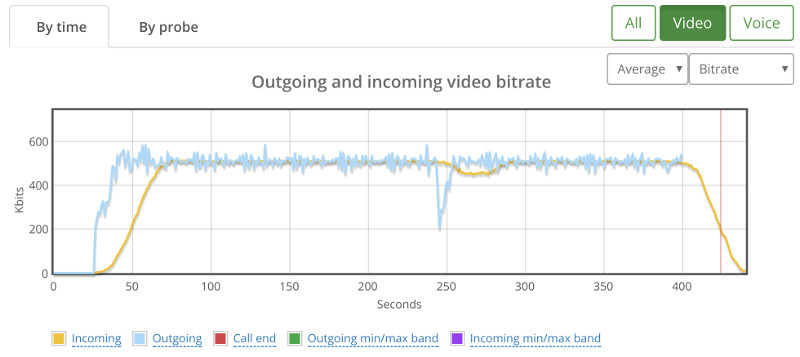
There wasn’t any packet loss to indicate why that drop with the broadcaster at around 240 seconds, so I switch to the “By probe” view.
This showed that things were starting to deteriorate somewhat:

We’re sorting the results just for this purpose – you can see there’s a slight decline in average bitrate across the probes here – something that is a lot less apparent for smaller test sizes. There was no packet loss.
We’ve tried going upwards to 200, but then 12 probes didn’t even connect properly:
Going down to a 100 yielded some connection errors in some of the probes as well. Specifically, I saw this one:

This indicates we’ve got a wee bit of an issue here that needs to be solved before we can continue our stress tests any further. Most probably in the signaling layer of our server. It is either unstable when we place so many viewers at once against it, or just doesn’t really handle the load well enough.
Results Summary
The table below shows the various limits we’ve reached in our rounds of sizing tests:
| Scenario | Size |
| 1:1 video calls | 18 users in 9 parallel sessions |
| 4-way group video calls | 3 rooms of 4 users each |
| Live broadcast | 1 broadcaster + 80-150 viewers |
What did we learn?
- Stress testing for sizing purposes is fun. I actually enjoyed going through the results and running a couple of tests of my own (I didn’t write the scripts or run the initial tests – I delegated that to our support engineer)
- Different scenarios will dictate very different sizing. With more time, I’d start working out on finding the bottlenecks and optimizing them – I’m sure more can be squeezed out of a Kurento machine
- Once set up and written intelligently, it’s really easy to rerun the tests and change the number of probes used
Next Steps
Once we got to the sweet spot in each scenario, the next thing to do would probably to run it more than once.
We usually setup a testRTC monitor to run once every 15 minutes to an hour for a couple of days on such a scenario, just to make sure we’re seeing stable results more than once.
Other than that, this needs to be tested under different network conditions, varying load factors, etc.
Check out our best practices for stress testing WebRTC applications. It is relevant even if you are not using testRTC
I’d like to thank WebRTC.ventures for the assistance in setting this one up. If you are looking for a capable vendor to custom build your WebRTC application – check them out.