
I am not sure about you, but I get bored easily when people tell me a bug costs more in production than it does earlier on in the development lifecycle. It sounds correct, but usually it comes with product managers and sales people throwing out $$$ amounts trying to make a point of it.
Being in a company offering testing and monitoring puts me in an awkward when I am supposed to actually use such tactics with customers. And I hate it. So I try to stick to fact. Real hard facts. This is why I found ClusterHQ’s recent survey about application testing so interesting. I do know this information comes in part from a company selling testing products. I am also aware that this is a survey that is rather small and not coming from the academia (a place where real products don’t get made). But it still resonates with me.
I liked the questions ClusterHQ asked, and wanted to share here two of these:
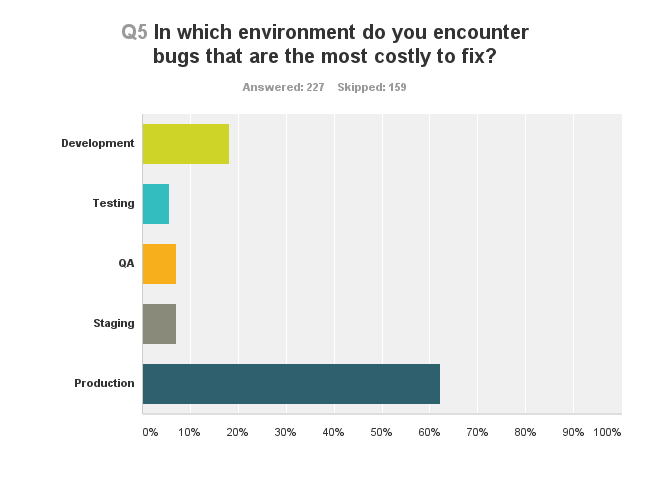
I guess there are no surprises here, besides maybe the people who think finding bugs in development is expensive.
There are two issues that make production bugs really expensive:
- If customers find them, then it means you have someone complaining already. This can lead to churn – customers leaving your service. If it something critical that affects a large number of your customers, then you’re screwed already
- To fix a bug in production takes time. You usually want to recreate it in on of your internal environments, then fix it, then test the whole damn application again to see that nothing else broke and then upgrade production again. This time eats resources – development, testing and management
It always happens. There is no way to really get away from bugs in production – the question though, is the frequency in which they occur. Which brings us to the next question in this survey.
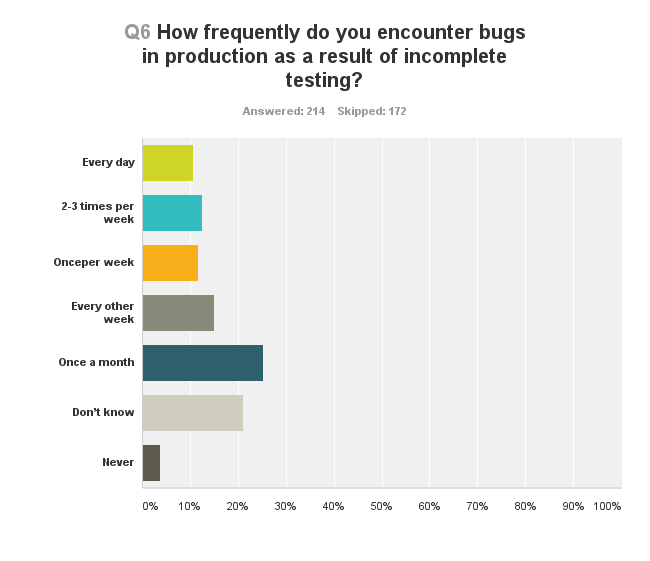
The frequency in which bugs are found in production. At these high rates, I wonder how things ever get solved.
With agile development, you can argue that these are non-issues. You are going to fix things on a daily or weekly basis, so anything found in production get squashed away rather fast and without too much of a hassle.
I am no expert in agile, but from looking at how WebRTC products are built, I think there are three areas where this approach is going to come back and bite you:
#1 – WebRTC relies on the browser
If your WebRTC product runs in a browser, then you relinquish some of your control to the browser vendors. And they are known to release their versions quite frequently (once every 6-8 weeks in an automated upgrade process). When it comes to WebRTC, they do tend to make changes that affect behavior and these may end up breaking your service.
How do you make sure you are not caught surprised by this? Do you test with the beta browser versions that are available? Do you make it a point to test this continuously or do you limit yourself to testing only when you release a new version?
#2 – More often than not, you rely on 3rd party frameworks (open source or commercial)
You use Kurento? Some other open source framework? Maybe a commercial product that acts as a media server or a gateway? A signaling framework you found on github? Or maybe it is a CPaaS vendors you opted for who is taking care of all communications for you.
Guess what – these things also need testing. Especially since you are using them in your own special way. I’ve been there, so I know it is hard to test every possible use case and every different way an API can be called. So thinks fall between the cracks.
When dealing with such issues and finding them in YOUR production – how long will it take that framework or product to be fixed so you can roll it out to your customers? Will it be at your development speeds or someone else’s?
#3 – Stress and Scale is devilishly hard to get right
Whenever someone starts using our service to test at scale, things break down. It can be minor things, like the fact that most services aren’t designed or built to get 10 people into the same session at the exact same moment (something that is hard to test so we rely on users just refreshing their browser). But it goes to serious issues, like degradation in bit rates and increase in packet losses the more people you throw on the service.
Finding these issues is one thing. Fixing it… that’s another one. Fixing large scale bugs is tough. It is tough because you need a way to reproduce them AND you need to find the culprit causing them.
If you don’t have a good way to reproduce large scale tests, then how are you supposed to be able to fix them?
What’s next?
If you end up using testRTC or not I leave for you to decide. We do have a product that takes care of many of the challenges when you test WebRTC products. So I invite you to try us out.
If you don’t – just do me a favor and take testing your product more seriously. When we work through evaluations, we almost often find bugs in production, and usually more than one. And that’s just from a single basic script we start with. It is time to look at WebRTC as more than a hobby.
Have you found serious bugs in production that you could have found and fixed if you tested WebRTC during development?