
I’ve seen this a few times already. People look at an automated process – only to replace it with a human one. For some reason, there’s a belief that humans are better. And grinding the same thing over and over and over and over and over again.
They’re not. And there’s a place for both humans and machines in WebRTC product testing.
WebRTC, Mechanical Turk and the lack of consistency
The Amazon Mechanical Turk is a great example. You can easily take a task, split it between many people, and have them do it for you. Say you have a list of a million songs and you wish to categorize them by genre. You can get 10,000 people in Amazon Mechanical Turk to do 100 lines each from that list and you’re done. Heck, you can have each to 300 lines and for each line (now with 3 scores), take the most common Genre defined by the people who classified it.
Which brings us to the problem. Humans are finicky creatures. Two people don’t have the same worldview, and will give different Genre indication to the same song. Even worse, the same person will give a different Genre to the same song if enough time passes (enough time can be a couple of minutes). Which is why we decided to show 3 people the same song to begin with – so we get some conformity in the decision we end up with on the Genre.
Which brings us to testing WebRTC products. And how should we approach it.
Here’s a quick example I gleaned from the great discuss-webrtc mailing list:

There’s nothing wrong with this question. It is a valid one, but I am not sure there’s enough information to work off this one:
- What “regardless of the amount of bandwidth” is exactly?
- Was this sent over the network or only done locally?
- What resolution and frame rate are we talking about?
- Might there be some packet loss causing it?
- How easy is it to reproduce?
I used to manage the development of VoIP products. One thing we were always challenged by is the amount of information provided by the testing team in their bug reports. Sometimes, there wasn’t enough information to understand what was done. Other times, we had so many unnecessary logs that you either didn’t find what was needed or felt for the poor tester who spent so much time collecting this stuff together for you with no real need.
The Tester/Developer grind cycle
Then there’s that grind:
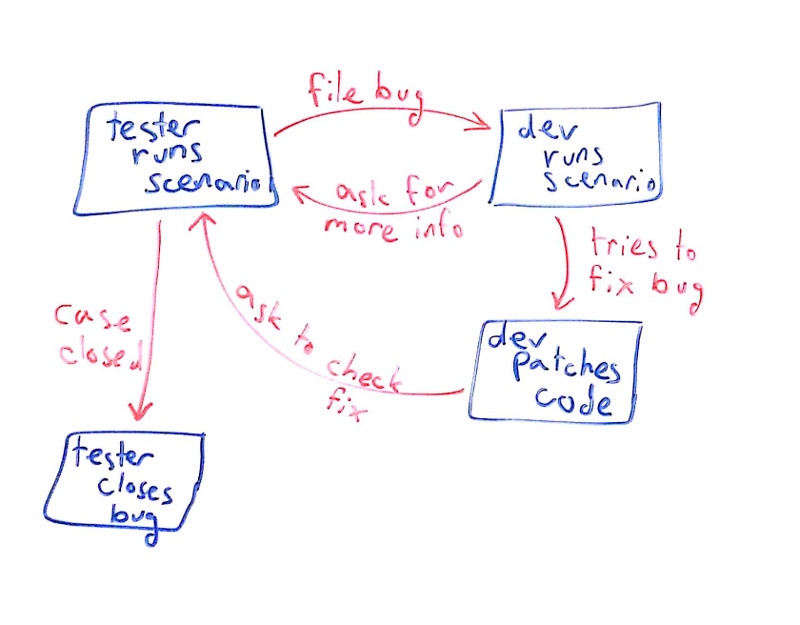
We’ve all been there. A tester finds what he believes is a bug. He files it in the bug tracking system. The developer can’t reproduce the bug, or needs more information, so the cycle starts. Once the developer fixes something, the tester needs to check that fix. And then another cycle starts.
The problem with these cycles is that the tester who runs the scenario (and the developer who does the same) are humans. Which makes it hard for repeated runs of the same scenario to end up the same.
When it comes to WebRTC, this is doubly so. There are just too many aspects that are going to affect how the test scenario will be affected:
- The human tester
- The machine used during the test
- Other processes running on said machine
- Other browser tabs being used
- How the network behaves during the test
It is not that you don’t want to test in these conditions – it is that you want to be able to repeat them to be able to fix them.
My suggestion? Mix and match
Take a few cases that goes through the fundamental flows of your service. Automate that part of your testing. Don’t use some WebRTC Mechanical Turk in places where it brings you more grief than value.
Augment it with human testers. Ones that will be in charge of giving the final verdict on the automated tests AND run around with their own scenarios on your system.
It will give you the best of both worlds, and with time, you will be able to automate more use cases – covering regression, stress testing, etc.
–
I like to think of testRTC as the Test Engineer’s best companion – we’re not here to replace him – just to make him smarter and better at his job.