How to Prepare Your WebRTC Application for a Surge in Traffic
OK, this is the moment you’ve been waiting for: there’s a huge surge in traffic on your WebRTC application. Success! You even had the prescience to place all of your web application’s assets on a CDN and whatever uptime monitoring service you use, be it New Relic, Datadog or a homegrown Nagios solution – says all is fine. But there’s just one nagging problem – users are complaining. More than they used to. Either because the service doesn’t work at all for them or the quality of the media just doesn’t cut it for them. What The–?!
We recently hosted a webinar about preparing for that big WebRTC launch. You might want to check the suggestions we made there as well.
Register now for free: WebRTC – How NOT to Fail in Your Big Launch
Let’s start by focusing on the positives here. Your service is being used be people. Then again, these people aren’t getting the real deal – the quality they are experiencing isn’t top notch. What they are experiencing is inability to join sessions, low bitrates or inexplicable packet losses. These are different than your run of the mill 500 and 502 errors, and you might not even notice something is wrong until a user complains.
So, what now?
Here’s what I’m going to cover today:
- Learn how to predict service hiccups
- Prepare your WebRTC application in advance for growth
Learn How to Predict Service Hiccups

While lots of users is probably what you are aiming for in your business, the effects they can have on your WebRTC application if unprepared for it can be devastating. Sure, sometimes they’ll force your service to go offline completely, but in many other times, the service will keep on running but it will deliver bad user experience. This can manifest itself by having users wait for long times to connect, requiring them to refresh the page to connect or just having poor audio and video quality.
Once you get to that point, it is hard to know what to do:
- Do you throw more machines on the problem?
- Do you need to check your network connections?
- How do you find the affected users and tell them things have been sorted out?
This mess is going to take up a lot of your time and attention to resolve.
Here is something you can do to try and predict when these hiccups are about to hit you:
Establish a Baseline
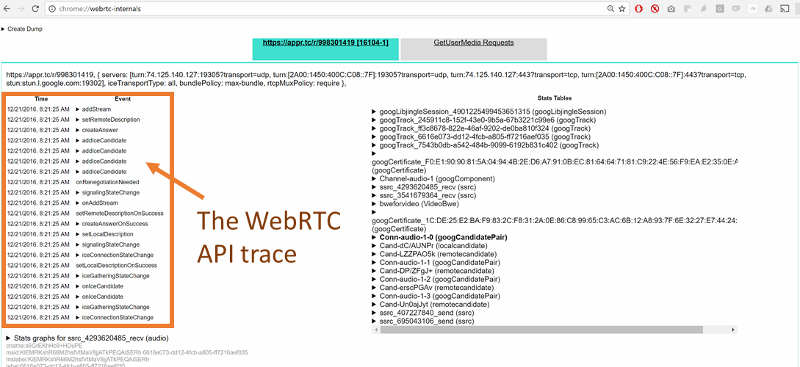
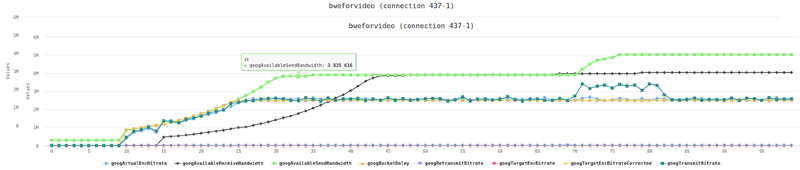
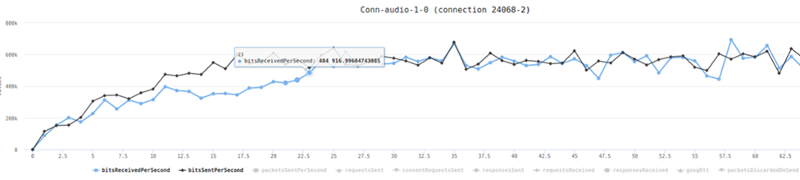
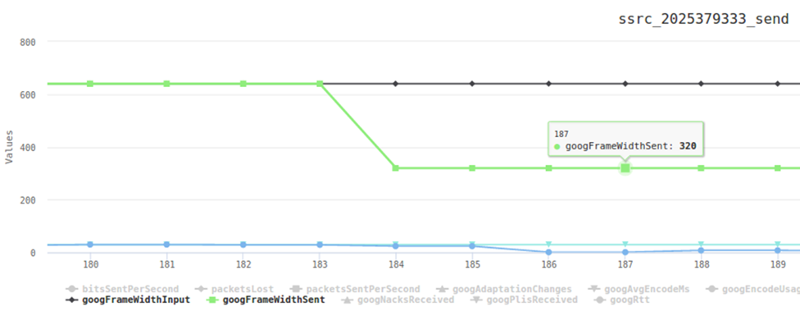
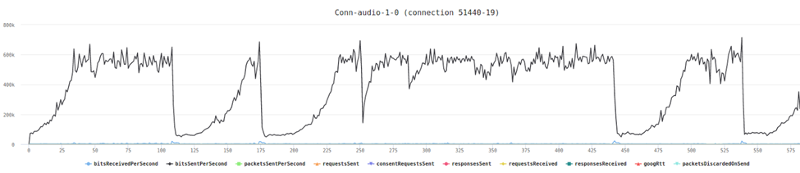
I’ve said it before and I’ll say it again. You need to understand the performance metrics of your WebRTC service. In order to do that, the best thing is to run it a bit with the acceptable load that you have and writing down for yourself the important metrics.
A few that come to mind:
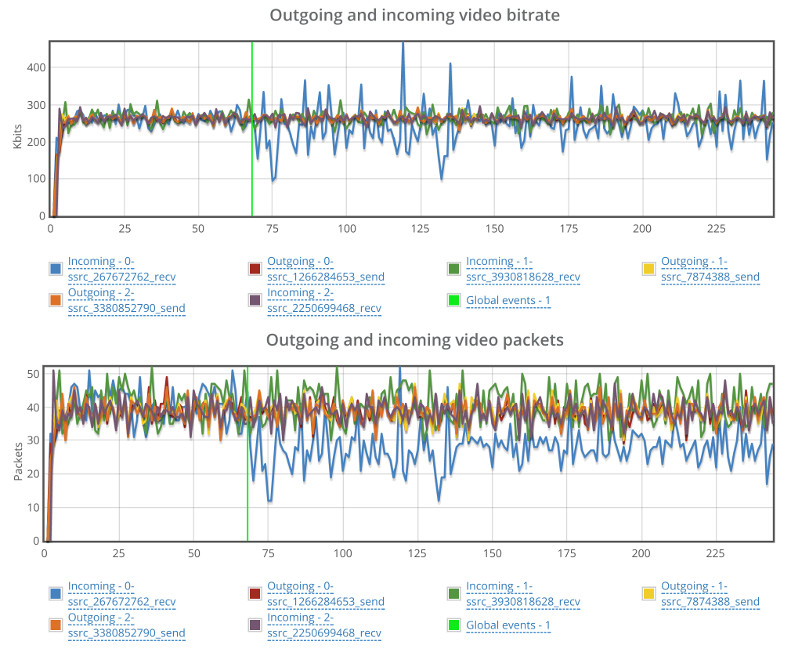
- Bitrate of the channels
- Average packet loss
- Jitter
Now that you have your baseline, take the time to gauge what exactly your WebRTC application is capable of doing in terms of traffic. How much load can it carry as you stack up more users?
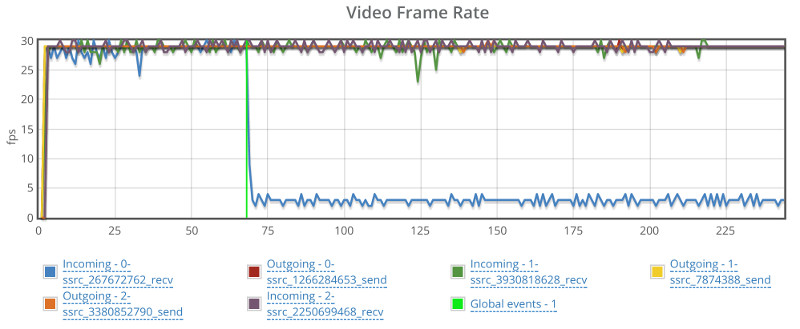
One neat trick you can do is place a testRTC monitor and use rtcSetTestExpectation() to indicate the thresholds you’ve selected for your baseline. Things like “I don’t expect more than 0.5% packet loss on average” or “average bitrate must be above 500kbps”. The moment these thresholds are breached – you’ll get notified and able to see if this is caused by growth in your traffic, changes in usage behavior, etc.
Prepare Your WebRTC Application in Advance for Growth

There aren’t always warning signs that let you know when a rampaging horde of users may come at your door. And even when there is, you better have some kind of a solution in place and be prepared to react. This preparation can be just knowing your numbers and have a resolution plan in place that you can roll out or it can be an automated solution that doesn’t require any additional effort on your end.
To get there, here are some suggestions I have for you.
Find Your System’s Limits
In general, there are 3 main limits to look at:
- How big can a single session grow?
- How many users can I cram into a single server?
- How many users can my service serve concurrently?
You can read more on strategies and planning for stress testing and sizing WebRTC services. I want to briefly touch these limits though.
1. How big can a single session grow?
Being able to handle 500 1:1 sessions doesn’t always scale to 100 groups of 10 users sessions. The growth isn’t linear in nature. On top of it, the end result might choke your server or just provide bitrates that are just too low above a certain number of users.
Make sure you know what’s the biggest session size you are willing to run.
Besides doing automated testing and checking the metrics against the baseline you want, you can always run an automated test using testRTC and at the same time join from your own browser to get a real feeling of what’s going on. Doing that will add the human factor into the mix.
2. How many users can I cram into a single server?
Most sizing testing are about understanding how many sessions/users/whatever can you fit in a single server. Once you hit that number, you should probably launch another server and use a load balancer to scale out.
Getting that number figured out based on your specific scenario and infrastructure is important.
3. How many users can my service serve concurrently?
Now that you know how to scale out from a single server, growing can be thought of as linearly (up to a point). So it is probably time to put in place automatic scale out and scale down and test that this thing works nicely.
Doing so will greatly reduce the potential and destruction that a service hiccup can cause.
CDN and Caching
Make sure all of the HTML assets of your WebRTC application that static are served through a CDN.
In some cases, when we stress test services, just putting 200 browsers in front of an HTML page that serves a WebRTC application can cause intermittent failures in loading the pages. That’s because the web serving part of the application is often neglected by WebRTC developers who are focusing their time and energy on the bigger resource hogs.
We’ve had numerous cases where the first roadblock we’ve hit with a customer was him forgetting to place a minor javascript file in the CDN.
Don’t be that person.
Geographically Distributed Deployment
The web and WebRTC are global, but traffic is local.
You don’t want to send users to the other side of the globe unnecessarily in your service. You want your media and NAT traversal servers to be as close to the users as possible. This gives you the flexibility of optimizing the backend network when needed.
Make sure your deployment is distributed along multiple datacenters, and that the users are routed to the correct one.
Philipp Hancke wrote how they do it at appear.in for their TURN servers.
Monitor Everything
CPU. Memory. Storage. Network. The works.
Add application metrics you collect from your servers on top of it.
And then add a testRTC monitor to check media quality end-to-end to make sure everything run consistently.
Check across large time spans if there’s an improvement or degradation of your service quality.
Stress Testing
Check your system for the load you expect to be able to handle.
Do it whenever you upgrade pieces of your backend, as minor changes there may cause large changes in performance.
Don’t Let Things Out of Your Control
WebRTC has a lot of moving parts in it so deploying it isn’t as easy as putting up a WordPress site. You should be prepared for that surge in traffic, and that means:
- Understanding the baseline quality of your service
- Knowing where you stand with your sizing and scale out strategy
- Monitoring your service quality so you can react before customers start complaining
Do it on your own. Use testRTC. Use whatever other tool there is at your disposal.
Just make sure you take this seriously.
We recently hosted a webinar about preparing for that big WebRTC launch. You might want to check the suggestions we made there as well.
Register now for free: WebRTC – How NOT to Fail in Your Big Launch